
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 가장 큰 수
- 코딩 테스트
- 루씬 인 액션
- @Setter
- 크론 표현식
- 알고리즘
- 검색 기능 확장
- 해시
- 정렬
- 기능개발
- K번째수
- 전화번호 목록
- Java
- 롬복 어노테이션
- kubenetes
- @Data
- 다리를 지나는 트럭
- 완주하지 못한 선수
- 커링
- @Getter
- @EnableScheduling
- 스프링 스케쥴러
- @configuration
- 스택/큐
- H-index
- 영속 자료구조
- 쿠버네티스
- 프로그래머스
- 고차원 함수
- 모던 자바 인 액션
Archives
- Today
- Total
Today I Learned
1장. 사용자 수에 따른 규모 확장성 본문
728x90
단일 서버
- 모든 컴포넌트(웹, 앱, 데이터베이스, 캐시 등)이 전부 한 대의 서버에서 실행되는 시스템
- 사용자의 요청 처리 흐름
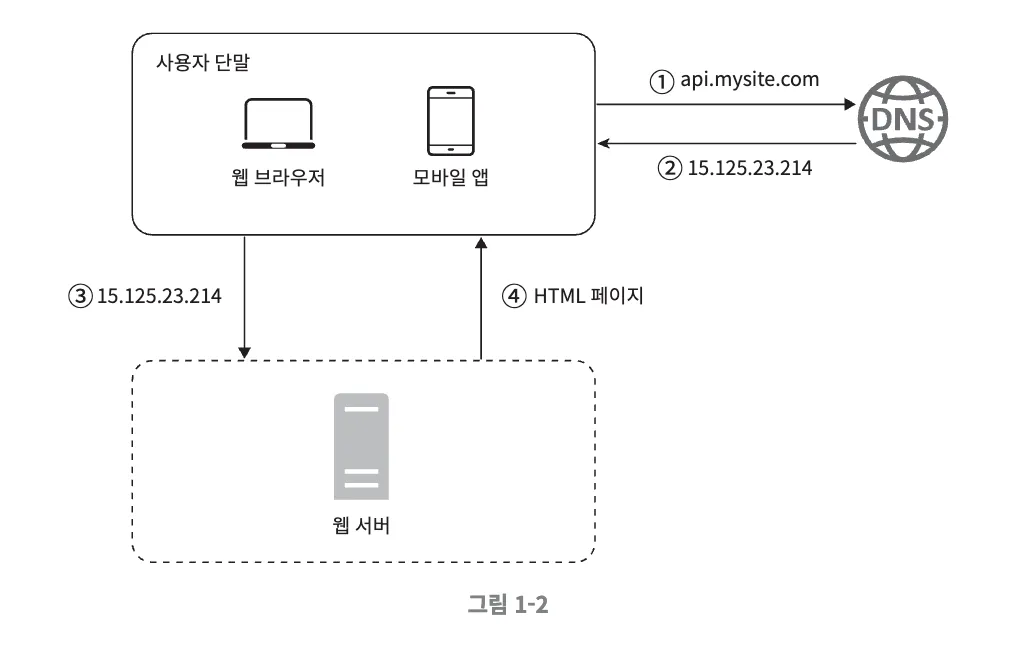
- 사용자가 도메인 이름으로 웹사이트에 접속
- DNS에 질의하여 도메인 이름을 IP주소로 변환
- 해당 IP 주소로 HTTP 요청이 전달
- 웹 서버에서 HTML 페이지, JSON 형태의 응답을 반환
데이터베이스
- 웹/모바일 트래픽 처리용 서버(웹 계층)와 데이터베이스용 서버(데이터 계층)를 분리

수직적 규모 확정 vs 수평적 규모 확장
- 대규모 애플리케이션에서 수평적 규모 확장이 적절한 이유
- 한 대의 서버에 CPU나 메모리를 무한대로 증설할 수 없음
- 자동 복구(failover) 방안이나 다중화 방한에 대한 문제
로드밸런서
- 부하 분산 집합(load balancing set)에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할

- 웹 사이트로 유입되는 트래픽이 커질 경우, 웹 서버 계층에 서버를 추가하면 로드밸런서가 트래픽을 분산
데이터베이스 다중화
- 데이터베이스 시스템을 master-slave 관계로 설정하고 원본은 주 서버, 사본은 부 서버에 저장
- 쓰기 연산은 마스터에서만 지원하며, 부 데이터베이스는 주 데이터베이스로부터 사본을 전달받음

- 장점
- 더 나은 성능 : 읽기 연산이 부 데이터베이스 서버들로 분산되어 병렬 처리
- 안정성 : 데이터를 분산 저장하므로 서버가 파괴되더라도 데이터가 보존
- 가용성 : 하나의 서버에 장애가 발생하더라도 다른 서버의 데이터로 서비스 가능
- 로드밸런서와 데이터베이스 다중화를 고려한 설계안
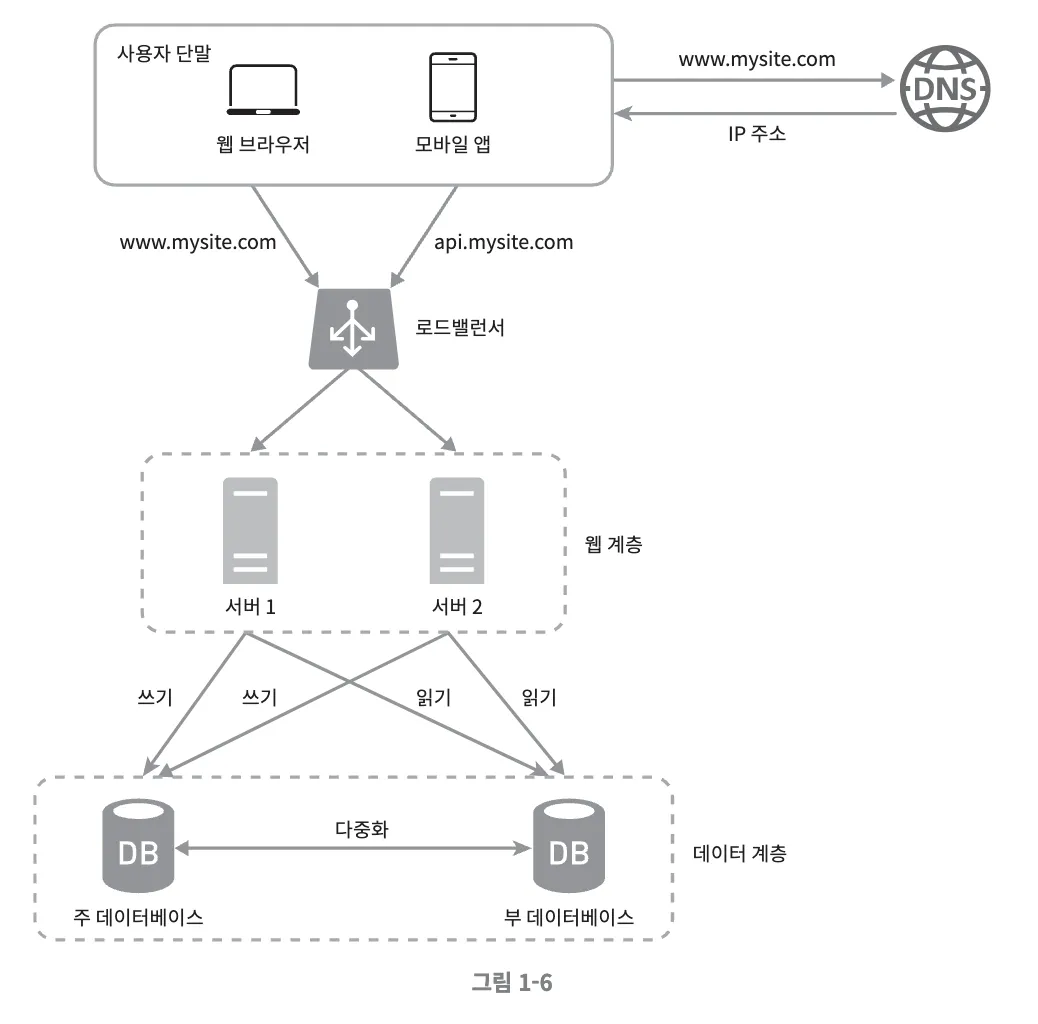
- 사용자는 DNS로부터 로드밸런서의 공개 IP 주소를 받아서 접속
- HTTP 요청이 서버1이나 2로 전달
- 웹 서버는 사용자의 데이터를 부 데이터베이스 서버에서 읽음
- 웹 서버는 데이터 변경 연산을 주 데이터베이스로 전달
캐시
- 값비싼 연산 결과 또는 자주 참조되는 데이터를 메모리 안에 두고 뒤이은 요청이 빠르게 처리될 수 있도록 하는 저장소
캐시계층

- 읽기 주도형 캐시 전략: 캐시를 먼저 확인한 후 없으면 데이터베이스에 질의하는 방식
캐시 사용 시 유의할 점
- 갱신은 자주 일어나지 않지만 참조는 빈번한 상황에 적합
- 만료 정책을 너무 짧게 두면 데이터베이스 조회가 늘어나고 너무 길면 원본과 차이날 가능성이 높아짐
- 단일 장애 지점(SPOF)를 피하기 위해 여러 지역에 캐시 서버를 분산시켜야 함

- 과할당을 통해 데이터가 너무 자주 밀려나는 문제를 방지할 수 있음
- LRU, LFU 또는 FIFO 같은 데이터 방출 정책을 지정해야함
콘텐츠 전송 네트워크(CDN)
- 정적 콘텐츠(이미지, 비디오, CSS 등)를 전송하는 데 쓰이는, 지리적으로 분산된 서버의 네트워크

- 사용자가 웹사이트에 방문하면, 그 사용자에게 가장 가까운 CDN 서버가 정적 콘텐츠를 전달
- 사용자가 CDN 서버로부터 멀면 멀수록 웹 사이트는 천천히 로드
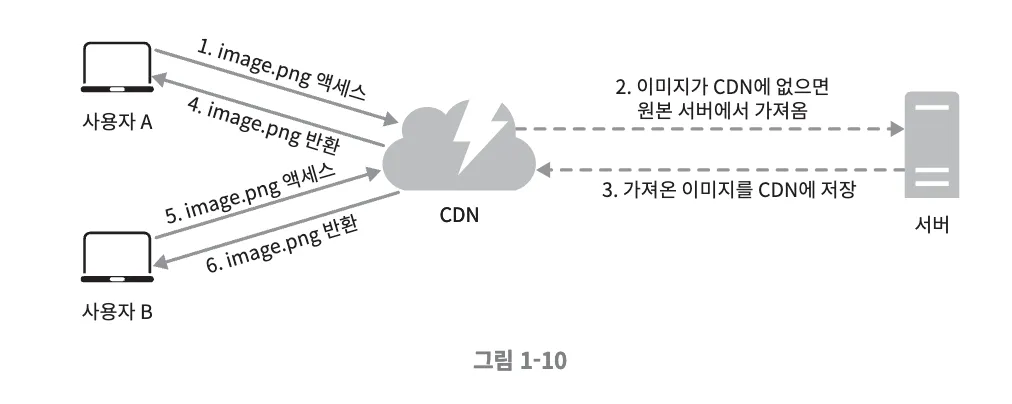
- 사용자 A가 CDN이 제공하는 URL을 이용해 이미지에 접근
- CDN 서버의 캐시에 해당 이미지가 없는 경우, 원본 서버에 요청해서 파일을 가져옴
- 원본 서버가 파일을 CDN에 반환
- CDN 서버는 파일을 캐시하고 사용자 A에게 반환. 이미지는 TTL에 명시된 시간까지 캐시
- 사용자 B가 같은 이미지에 대한 요청을 CDN 서버에 전송
- 만료되지 않은 이미지에 대한 요청은 캐시를 통해 처리
CDN 사용 시 고려해야 할 사항
- 비용, 적절한 만료 시한 설정, CDN 장애 시 대처 방안, 콘텐츠 무효화 방법
CDN과 캐시가 추가된 설계

- 정적 콘텐츠는 웹 서버 대신 CDN을 통해 제공
- 캐시가 데이터베이스 부하 분산
무상태(stateless) 웹 계층
- 웹 계층의 수평적 확장을 위해서는 상태정보(ex. 사용자 세션 데이터)가 없어야 함
- 상태 정보는 DB에 보관하고 필요 시 가져오도록 함
상태 정보 의존적인 아키텍처
- 상태 정보를 보관하는 서버는 클라이언트 정보가 요청들 사이에 공유되어야 함

- 같은 클라이언트로부터의 요청은 항상 같은 서버(해당 클라이언트의 정보가 저장되어있는)로 전송되어야 함
- 이를 위해 로드밸런서는 고정 세션(sticky session) 기능을 제공하지만, 부하가 존재함
- 로드밸런서 뒷단에 서버를 추가하거나 장애 처리하는 과정이 복잡해짐
무상태 아키텍처

- 사용자의 요청이 어떤 웹 서버로도 전송 가능
- 상태 정보는 공유 저장소에 저장
- 단순하고, 안정적이고, 규모 확장이 쉬움
무상태 웹 계층을 적용한 설계
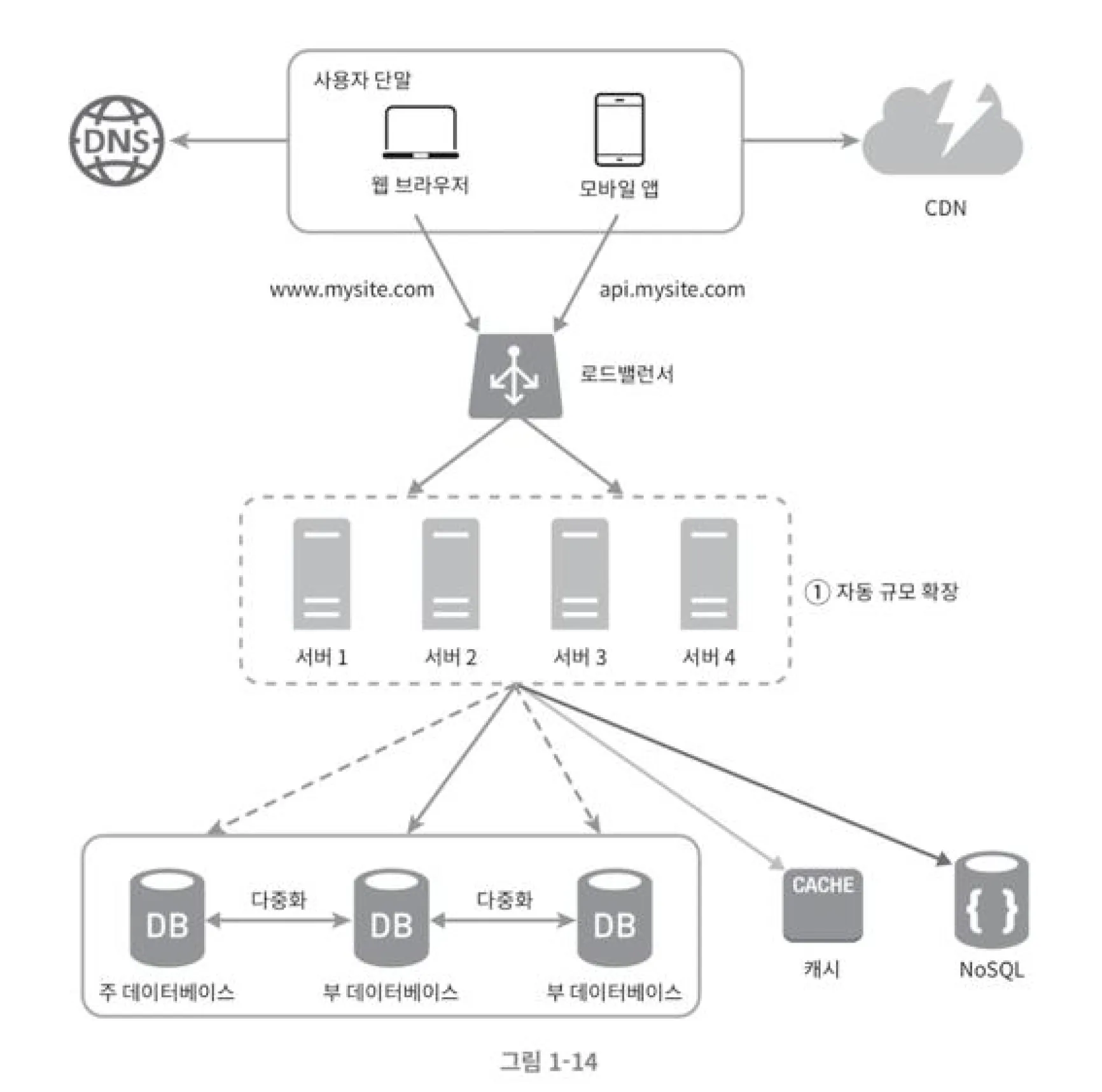
데이터 센터
- 장애가 없는 상황에서 사용자는 지리적 라우팅(geoDns-routing)에 따라 가까운 데이터 센터로 연결

다중 데이터센터 아키텍처 설계 시 고려해야 할 사항
- 트래픽 우회, 데이터 동기화, 테스트와 배포
메시지 큐
- 메시지의 무손실, 비동기 통신을 지원하는 컴포넌트
- 메시지큐를 사용하면 서비스 간의 결합이 느슨해져서, 규모 확장이 용이해짐

- 생산자(또는 발행자)라고 불리는 입력서비스가 메시지를 만들어 메시지 큐에 발행
- 소비자(또는 구독자)라고 불리는 서비스가 메시지를 받아 그에 맞는 동작을 수행
로그, 메트릭 그리고 자동화
- 로그: 시스템의 오류와 문제들을 쉽게 찾아낼 수 있음. 로그를 단일 서비스로 모아주는 도구를 활용하면 편리하게 조회 가능
- 메트릭: 사업 현황이나 시스템의 현재 상태를 손쉽게 파악 가능
- 자동화: 빌드, 테스트, 배포 등의 절차를 자동화시켜 개발 생산성을 높일 수 있음
메시지 큐, 로그, 메트릭, 자동화 등을 반영하여 수정한 설계안

데이터베이스의 규모 확장

수직적 확장
- 기존 서버에 더 많은, 또는 고성능의 자원(CPU, RAM, 디스크 등)을 증설하는 방법
- 단점
- 서버 하드웨어의 한계가 있어 자원을 무한 증설할 수는 없음
- SPOF(Single Point of Failure)로 인한 위함성
- 고성능 서버로 갈수록 비용이 증가
수직적 확장
- 더 많은 서버를 추가함으로써 성능을 향상시키는 방법
- 샤딩: 대규모 데이터베이스를 샤드(shard)라고 부르는 작은 단위로 분할하는 기술
- 샤딩 키(sharding key)에 따라 어떤 데이터베이스에 데이터를 넣을지 결정

샤딩 도입 시의 문제
- 데이터의 재 샤딩
- 데이터가 너무 많아져서 샤드를 추가해야할 때
- 샤드 간 데이터 분포가 균동하지 못하여 할당된 공간 소모가 다른 샤드에 비해 빠를 때
- 이런 현상이 발생하면 샤드 키를 계산하는 함수를 변경하고 데이터를 재배치해야 함
- 핫스팟 키 문제
- 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제
- 각각의 샤드에 핫스팟 키를 저장해야 함
- 조인과 비정규화
- 여러 샤드에 걸친 데이터는 조인하기 어려워짐
- 데이터베이스를 비정규화여 하나의 테이블에서 질의가 수행되도록 해야 함
데이터베이스 샤딩을 적용한 아키텍처

728x90
'설계 > System Design Interview Volume 1' 카테고리의 다른 글
| 2장. 개략적인 규모 추정 (0) | 2025.07.10 |
|---|
'설계/System Design Interview Volume 1' Related Articles
more

Comments