
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 커링
- @configuration
- @Getter
- @EnableScheduling
- 크론 표현식
- 다리를 지나는 트럭
- 프로그래머스
- 기능개발
- 롬복 어노테이션
- 루씬 인 액션
- 스택/큐
- 가장 큰 수
- 모던 자바 인 액션
- 완주하지 못한 선수
- @Setter
- 해시
- kubenetes
- 알고리즘
- 코딩 테스트
- H-index
- 정렬
- Java
- K번째수
- @Data
- 고차원 함수
- 검색 기능 확장
- 스프링 스케쥴러
- 전화번호 목록
- 쿠버네티스
- 영속 자료구조
- Today
- Total
Today I Learned
[루씬 인 액션] 2장. 색인 본문
2장에서 다루는 내용
- 기본적인 색인 작업
- 색인 과정에서 문서나 필드에 중요도 지정
- 날짜, 숫자 필드, 정렬 가능한 필드
- 고급 색인 기법
2.1 루씬 데이터 모델
2.1.1 문서와 필드
문서
- 루씬에서 색인과 검색 작업을 진행할 때 한 건이라고 부를 수 있는 단위
- 하나 또는 그 이상의 필드를 담고 있으며, 필드 안에 실제 내용이 들어감
- 각 필드마다 이름을 지정, 텍스트나 바이트 배열이 값으로 들어감
- 색인에 필요한 설정들을 포함
ex) 검색 조건 'title:lucene' → title이란 필드에 lucene이란 단어가 들어있는 문서를 조회
루씬의 필드 설정
- 필드의 내용을 색인할지 설정
- 필드의 텀 벡터(term vector)를 저장할지 설정(필드의 내용을 색인하는 경우)
- 색인 여부와 관계없이 필드의 내용을 저장할 것인지 설정
색인에 저장한 필드만 문서에 들어오며, 저장하지 않은 필드는 검색 결과에 미포함
2.1.2 유연한 스키마
데이터베이스와 달리 루씬은 별도의 스키마가 존재 X → 문서 객체마다 서로 다른 필드 구조를 가지더라도 문제없음
2.1.3 비정규화
루씬의 색인에 추가하려는 정보는 모두 텍스트로 변환하고 비정규화(denormalize)해야함
2.2 색인 절차

2.2.1 텍스트 추출과 문서 생성
원본 문서에서 텍스트를 추출하여 Field 객체와 Document 객체를 생성
2.2.2 분석
Document에 포함된 텍스트를 토큰으로 분리하고, LowerCaseFilter, StopFilter 등의 토큰 필터를 적용
2.2.3 색인에 토큰 추가
토큰을 역파일 색인(inverted index) 구조로 저장
* 역파일 색인 : 질의한 단어가 포함하고 있는 문서를 조회하는데 최적화된 자료구조
색인 세그먼트
루씬의 색인 하나는 다수의 세그먼트(segment)로 구성
각 세그먼트는 개별적인 색인이며, 전체 색인에 들어있는 문서 중 일정량을 담음

세그먼트는 _X.<확장자> 형태의 파일명으로 구성되며, 텀 벡터 파일, 필드 파일, 역파일 색인 파일 등 파일이 담당하는 기능에 따라 확장자를 지정
* segments_<N> : 해당 색인을 구성하는 모든 세그먼트에 대한 참조를 보관. 색인을 열 때 가장 먼저 읽는 파일.
<N> 값은 '세대(generation)'이라 부르며, 색인에 변경사항이 반영될 때마다 하나씩 증가하는 정수값.
IndexWriter 클래스에서 추가하거나 삭제한 문서를 버퍼에 쌓아두었다가 플러시(flush)하면 새로운 세그먼트를 생성
생성된 세그먼트는 주기적으로 병합(MergePolicy 클래스와 MergeScheDuler 클래스)
검색 시 각 세그먼트의 조화 결과를 합쳐서 출력
2.3 기본 색인 작업
2.3.1 색인에 문서 추가
- addDocument(Document) : 기본 분석기를 사용해 문서를 색인에 추가
- addDocumnet(Document, Analyzer) : 인자로 지정한 분석기를 사용해 문서를 색인에 추가. 색인 분석기와 검색 분석기가 다르면 검색결과가 올바르게 나오지 않을수 있음에 주의.
2.3.2 색인에서 문서 삭제
- deleteDocuments(Term / Query) : 지정한 텀 / 질의를 포함하는 모든 문서를 삭제
- deleteDocuments(Term{} / Query{}) : 지정한 배열에 담긴 텀 / 질의 중 하나라도 포함하는 모든 문서를 삭제
- deleteAll() : 해당 색인에 들어있는 모든 문서를 삭제
- maxDoc() : 삭제 표시가 된 문서를 포함한 모든 문서의 개수
- numDoc() : 삭제 표시가 없는 문서의 개수
특정 문서만 정확하게 삭제하고자 한다면, 식별자 필드를 준비하고 문서마다 유니크하게 관리해야함
writer.deleteDocuments(new Term("ID", documentId));
문서 삭제 시 메모리 버퍼 보관했다가 주기적으로 Directory 반영(문서 삭제 여부만 표시)
2.3.2 색인에서 문서 변경
문서 변경 시, 해당 문서를 삭제 후 재색인(특정 필드만 변경하는 기능 지원 X)
- updateDocuments(Term, Document) : 지정한 term 객체에 해당하는 모든 문서를 삭제하고, 기본 설정된 분석기를 사용해 문서 추가
- updateDocuments(Term, Document, Analyzer) : 지정한 term 객체에 해당하는 모든 문서를 삭제하고, 인자로 지정한 분석기를 사용해 문서 추가
2.4 필드별 설정
2.4.1 색인 관련 설정
역파일 색인 생성 시 처리하는 방법을 지정
- Index.ANALYZED : 필드에 지정된 텍스트를 분석기에 넘겨 일련의 토큰을 추출. 일반적인 텍스트 필드에서 사용(본문, 제목, 요약 등)
- Index.NOT_ANALYZED : 분석기 처리 없이, 텍스트 전체를 하나의 토큰으로 간주(파일 경로, 날짜, 사람 이름, 주민번호, 전화번호 등)
- Index.ANALYZED_NO_NORMS / Index.NOT_ANALYZED_NO_NORMS : norm 값을 색인에 저장하지 않음
* norm : 색인할 때 지정했던 중요도를 색인에 보관. 검색 시 메모리 소모 ↑ - Index.NO : 색인안함
Field.setOmitTermFreqAndPositions(true) 메소드
- 벡터 공간 모델의 텀 빈도수, 텀 위치 등을 저장하지 않는 옵션
- 해당 필드에 불리언 검색만 실행할 예정일 때 사용
- 디스크 공간 절약, 검색 및 필터 적용 시간 단축
- PhraseQuery나 SpanQuery처럼 텀의 위치 정보가 필요한 검색기능은 사용 불가
2.4.2 필드의 원문 저장 관련 설정
- Store.YES : 필드의 텍스트를 색인에 저장. 검색 결과를 화면에 표시할 때 사용할 값에 사용(링크할 URL, 제목, 원본 DB의 PK 등)
- Store.No : 필드의 텍스트를 색인에 저장 X. 검색 결과 화면에 보여주지 않아도 되는 내용에 사용(웹페이지 본문 등)
CompressionTools 클래스
- 필드의 내용을 압축해 저장
- 디스크 공간 절약 / 색인 및 검색 속도 저하 / 텍스트 길이 짧을땐 압축효과 낮음
2.4.3 텀 벡터 관련 설정
텀 벡터란?
문서의 ID와 텀을 키로 사용하며, 특정 문서 내부에서 해당 문서만의 역파일 색인을 구성한 것과 같다.
텀 정보는 필드 내용 하이라이팅 속도 개선, 비슷한 문서 찾기 기능 등을 사용 등에 활용할 수 있다.
- TermVector.Yes : 문서 내의 모든 텀과 텀 개수를 저장
- TermVector.WITH_POSITIONS : 문서 내의 모든 텀과 텀 개수, 각 텀의 위치를 저장
- TermVector.WITH_OFFSETS : 문서 내의 모든 텀과 텀 개수, 각 텀의 오프셋을 저장
- TermVector.WITH_POSITIONS_OFFSETS : 문서 내의 모든 텀과 텀 개수, 각 텀의 위치 및 오프셋을 저장
- TermVector.NO : 텀 벡터 정보 저장안함
2.4.4 Reader, TokenSteram, byte[] 필드
String 텍스트 대신 다른 형태로 색인할 내용을 지정할 수 있음
- Field(String name, Reader value, TermVector termVector) : String 대신 Reader 객체를 인자로 지정. 내용이 길때 사용 [Store.NO]
- Field(String name, Reader value) : 위와 동일 [Store.NO / TermVector.NO]
- Field(String name, TokenStream tokenStream, TermVector termVector) : tokenStream 객체로 미리 분석 절차를 거침 [Store.NO]
- Field(String name, TokenStream tokenStream) : 위와 동일 [Store.NO / TermVector.NO]
- Field(String name, byte[] values, Store store) : 이진 데이터를 저장 시 사용 [Store.YES / Index.No / TermVector.NO]
- Field(String name, byte[] values, int offset, int length, Store store) : 위와 동일하나 바이트 배열 중 offset 인자와 length 인자만 사용
2.4.5 유용한 필드 설정 조합

2.4.6 정렬 관련 설정
정렬 기준으로 사용할 필드는 반드시 색인해야 하며, 해당 필드에 문서 당 하나의 토큰만 있어야함
2.4.7 다중 값 필드
값마다 이름이 같은 별도의 필드 객체를 생성하거나, 값을 하나로 연결해서 처리
한 문서에 동일한 이름의 필드가 있는 경우 연관도 점수를 조절하는 등의 설정도 가능
2.5 문서와 필드 중요도
루씬은 필드의 텍스트가 짧을수록 / 토큰의 개수가 적을수록 중요도를 높게 책정
2.5.1 문서 중요도
- Doc.setBoost(float) : 문서의 중요도를 부여
2.5.2 필드 중요도
- Field.setBoost(float) : 필드의 중요도를 부여
2.5.3 norm
색인 작업 시 각 필드의 중요도 값을 취합하여 보관
- setNorm : norm 값을 지정
norm 값 사용 시 검색 메모리 사용량 증가(검색 필드 개수 * 전체 문서의 개수 만큼의 바이트 수 확보 필요)
하나의 필드라도 norm 값을 사용한다면 모든 필드가 norm 저장 공간 1byte씩을 할당해두므로, 미사용한다면 재색인 필요
2.6 숫자, 날짜, 시각 색인
2.6.1 숫자 색인
- 숫자 하나를 미리 정의된 공간(bracket)에 할당하는 트라이(trie) 구조로 색인
- 각 공간은 유일한 텀을 사용해 색인에 보관하여, 빠른 검색 가능(숫자 범위 검색, 필터 처리)
1. 텍스트에 숫자가 포함되는 경우
- 숫자를 단일 토큰으로 분리 : WhitespaceAnalyzer, StandardAnalyzer
- 텍스트에서 숫자를 제거 : SimpleAnalyzer, StopAnalyzer
2. 텍스트 없이 숫자만 있는 경우 : NumericField
2.6.2 날짜, 시각 색인
날짜와 시각을 int, long 자료형으로 변환 후, NumericField로 처리하여 색인
2.7 필드 길이
- maxFieldLength 값으로 색인할 대상 텍스트 길이를 제한 가능
- 메모리와 디스크 사용량을 통제하기 위해 사용
- 지정된 길이 이후의 텀은 무시되므로 주의
2.8 준실시간 검색
색인한 문서를 즉시 검색할 수 있는 기능
- IndexReader getReader()
- 버퍼의 변경 사항을 색인에 반영한 후 , 반영 내용을 담고있는 IndexReader 인스턴스를 리턴
- 기존의 세그먼트에 변경사항만 추가로 읽기 때문에 속도가 빠름
2.9 색인 최적화
검색 = 각 세그먼트 개별 검색 + 취합
최적화를 통해 세그먼트 수를 최소화하면 검색 속도↑
최적화 작업은 검색 속도를 향상시켜주지만, 색인 속도에는 영향이 없다.
(어차피 색인 요청시마다 신규 세그먼트로 만드니까?)
IndexWriter 클래스 최적화 관련 메소드
- optimize() : 색인의 세그먼트를 1개로 병합
- optimize(int maxNumSegments) : 세그먼트를 인자 개수 이하로 병합
- optimize(boolean doWait) : false 지정 시, 병합 작업을 백그라운드에서 수행. 별도의 병합 스케쥴러가 필요
- optimize(int maxNumSegments, boolean doWait) : 최대 세그먼트 수 지정 + 백그라운드 병합
최적화 작업 시 최대 3배의 디스크 공간이 필요 (병합 세그먼트 신규 생성 → 기존 세그먼트 삭제)
2.10 여러 종류의 Directory

FSDirectory 하위 클래스(FileSystem)
- SimpleFSDirectory : 파일 내부 위치 지정 기능이 없어 락 사용.
- NIOFSDirectory : 파일 내부 위치 지정 기능이 있어 락 X
- MMapDirectory : 색인의 크기 만큼 메모리 공간이 필요하기 때문에 64비트 JRE가 권장됨. 자바에서는 가비지컬렉션이 동작해야 메모리가 해제된다는 것도 주의!
- FSDirectory .Open : 환경에 따라 가장 적절한 Directory 클래스를 생성
- RAMDirectory : 속도 향상되나 요즘은 파일 I/O 시에도 여유 메모리를 버퍼로 사용하기 때문에 큰 차이 없음.
2.11 병렬 처리, 스레드 안정성, 락
- 다수의 JVM에서 하나의 색인을 동시에 사용하는 문제
- IndexReader와 IndexWriter를 동시에 사용할 때 스레드 안정성 문제
- 몇가지 규칙을 적용하고자 사용하는 락
2.11.1 스레드와 다중 JVM 안정성
루씬의 병렬 처리 규칙
- 색인마다 IndexReader는 여러개 사용 가능
- 색인마다 IndexWriter는 하나만 사용 가능
- IndexWriter가 실행중이더라도 IndexReader 사용 가능. 최종 커밋 시점의 색인 버전으로 열림
- IndexReader와 IndexWriter는 여러 스레드에서 공유 가능. thread safety를 보장함

2.11.2 원격 파일 시스템의 색인 공유
각 장비에서 원격으로 연동하는 방법도 있지만, 성능을 위해 원본 색인의 사본을 각 검색 서버에 확보하는 방법이 권장됨
원격 파일 시스템의 색인을 그대로 사용 시, 클라이언트 캐시 문제가 발생할 수 있음

2.11.3 색인 락

락 공정성을 처리하려면 락 생성 클래스를 직접 구현해야 함.
IndexWriter 락 관련 메소드
- isLocked(Directory) : 지정한 Directort의 색인이 락 상태인지 확인
- unlock(directory) : 락을 강제로 해제
2.12 색인 작업 디버깅
- IndexWriter.setInfoStream : 색인 진행 내용을 PrintStream으로 출력
2.13 고급 색인 기법
2.13.1 IndexReader에서 문서 삭제
| 기능 | IndexReader | IndexWriter |
| 문서 번호로 삭제 | 가능 | 불가 (병합 과정에서 문서 번호 바뀜) |
| Term으로 삭제 | 가능(삭제 문서 수 리턴) | 가능(삭제 문서 수 알수없음 - 버퍼에 쌓였다가 나중에 적용) |
| 검색 결과 반영 | 즉시 반영 | IndexReader 다시 열때 반영 |
| 삭제 롤백 | 가능(병합 전의 세그먼트 문서) | 가능(병합 전의 세그먼트 문서) |
IndexReader로 문서 삭제 시에도 쓰기 락을 확보해야하기 때문에, 일반적으로는 IndexWriter에서 일괄 처리하는게 효율적
2.13.2 삭제된 문서가 차지하는 디스크 공간
문서 삭제 여부만 표시하였다가 optimize 호출 시 또는 자동 병합 시에 디스크에서 삭제 처리
- expungeDeletes : 삭제 문서 세그먼트를 병합하여 디스크에서 삭제
2.13.3 문서 버퍼, 플러시
문서 변경 시 메모리 버퍼에 보관했다가 주기적으로 디스크에 플러시(flush)

세그먼트를 새로 생성하는 케이스
- setRAMBufferSizeMB : 지정된 버퍼의 용량을 초과하면 디스크에 플러시
- setMaxBufferedDocs : 지정된 최대 문서를 초과하면 디스크에 플러시
- setMaxBufferedDeleteTrms : 지정된 최대 삭제 텀, 질의 수를 초과하면 디스크에 플러시
IndexWriter.DISABLE_AUTO_FLUSH : 자동 플러시 제한 인자
루씬의 기본설정 : 메모리 16MB 초과 시 자동 플러시
플러시했더라도 커밋 전까지는 변경사항이 검색결과에 반영되지 않음
2.13.4 색인 커밋
IndexWriter 커밋 절차
- 메모리 버퍼의 모든 신규 문서와 삭제 문서를 플러시
- 이전 커밋 이후의 모든 신규 파일 및 병합 파일을 싱크.
- Directory.sync 메소드를 호출하여, 디스크 쓰기작업이 끝나면 return
- 다음 번호의 segments_N 파일을 생성하고 디스크에 싱크 이 작업이 끝나면 새 IndexReader부터 반영
- 기존 커밋 제거(IndexDeletionPolicy의 설정을 따름)
2단계 커밋
분산 2단계 커밋으로 루씬의 색인과 데이터 베이스 등의 외부 저장소를 트랜잭션으로 연동 가능
- prepareCommit() : 1~3 작업까지 완료 후, segments_N 파일을 IndexReader에 노출하지 않은 상태
- commit() 또는 rollback() : 트랜잭션 처리
IndexDeletionPolicy
기존 커밋 색인에 대한 삭제 여부를 관리
- KeepOnlyLastCommitDeletionPolicy : 최신 커밋 완료 후 이전 커밋 모두 삭제
별도의 설정 필요 시, IndexDeletionPolicy 클래스를 직접 구현해서 사용 가능
다수의 커밋을 관리하는 API
색인 하나에 여러 개의 커밋을 보관 가능
- IndexReader.listCommits() : 색인의 커밋 목록 조회
이전 커밋의 IndexReader 객체 생성 및 색인 검색 가능
이전 커밋의 IndexWriter 객체로 변경 사항 롤백 가능
2.13.5 ACID 트랜잭션과 색인의 일관성
루씬은 ACID 트랜잭션 모델을 구현하며, 한번에 하나의 트랜잭션(IndexWriter)만 처리
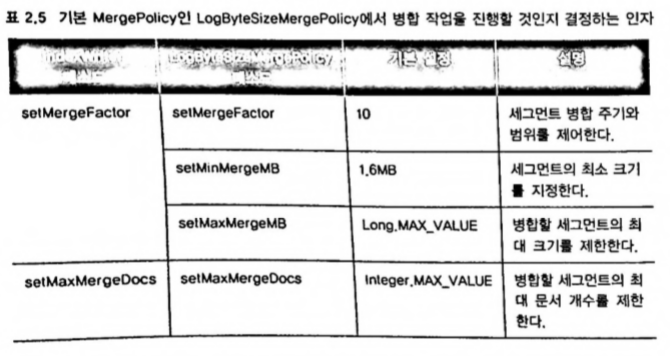
2.13.6 병합
세그먼트 병합의 장점
- 세그먼트 개수가 줄어든다. 검색 질의 실행 횟수가 줄어들어 검색 성능이 빨라지고, 운영체제의 파일 개방 제한에 유연한 대처 가능
- 색인이 차지하는 디스크 공간이 줄어든다. 삭제 문서를 디스크에서 제거하고 및 중복 문서를 병합
MergePolicy
병합 시점인지 판단하여 병합 대상 세그먼트를 추출하고, 병합을 실행
- LogByteSizeMergePolicy : 특정 세그먼트에 해당하는 모든 색인 파일의 바이트 크기에 따라 동작
- LogDocMergePolicy : 세그먼트의 문서 개수에 따라 동작
두 MergePolicy 모두 삭제 문서 개수는 신경쓰지 않음
세그먼트 적용 공식 :

MergeScheduler
실제 병합 작업을 처리
ConcurrentMergeScheduler : 백그라운드 스레드를 활용해 병합
SerialMergeScheduler : 호출하는 스레드에서 직접 병합
2.14 정리
2장에서 다룬 내용
- 루씬이 문서와 필드를 모델링하는 개념, 루씬의 단순한 스키마 관리 구조
- 원본 문서 수집, 텍스트 본문 추출, 텍스트 기반의 필드와 문서 생성
- 필드 내용 분석 및 토큰으로 분리, 색인에 문서 추가
- 색인을 구성하는 세그먼트 구조
- 색인에 문서 추가, 삭제, 변경
- 다양한 필드 설정 방법
- 세그먼트 최적화 작업 및 삭제 문서 공간 활용
- 다양한 Directory 구현 객체와 차이점
- 루씬의 병렬 처리 규칙과 쓰기 락
'루씬 Lucene' 카테고리의 다른 글
| [루씬 인 액션] 6장. 검색 기능 확장 (0) | 2021.01.26 |
|---|---|
| [루씬 인 액션] 5장. 고급 검색 기법 (0) | 2021.01.10 |
| [루씬 인 액션] 4장. 루씬의 텍스트 분석 (0) | 2020.12.08 |
| [루씬 인 액션] 3장. 검색 (0) | 2020.11.23 |
| [루씬 인 액션] 1장. 루씬과의 만남 (0) | 2020.11.03 |



