
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 기능개발
- 스택/큐
- 영속 자료구조
- K번째수
- Java
- 커링
- 다리를 지나는 트럭
- 쿠버네티스
- 완주하지 못한 선수
- 가장 큰 수
- 전화번호 목록
- 검색 기능 확장
- 루씬 인 액션
- @EnableScheduling
- @Setter
- @configuration
- 크론 표현식
- 해시
- kubenetes
- 고차원 함수
- 정렬
- 스프링 스케쥴러
- @Getter
- H-index
- 프로그래머스
- 롬복 어노테이션
- @Data
- 모던 자바 인 액션
- 코딩 테스트
- 알고리즘
- Today
- Total
Today I Learned
[루씬 인 액션] 4장. 루씬의 텍스트 분석 본문
4장에서 다루는 내용
- 텍스트 분석 과정
- 분석 관련 핵심 클래스
- 분석기 작성 방법
- 다국어 처리 방법
루씬의 분석과정 : 필드에 지정된 텍스트를 색인 내부에서 사용하는 가장 기본적인 단위인 텀으로 분리하는 작업
4.1 분석기 활용
- 텍스트를 텀으로 분리해야 할때 분석기 사용
- 색인 작업 시
- QueryParser 검색 시
- 문서 요약본 하이라이트 기능


- 색인 과정에서는 분리한 토큰에 필드 이름을 더해 텀으로 생성
분석기 별 특성 요약
- WhitespaceAnalyzer : 텍스트를 공백문자 기준으로 토큰 분리. 별도 정규화 없음
- SimpleAnalyzer : 알파벳이 아닌 모든 글자를 기준으로 토큰 분리. 각 토큰은 소문자 변경. 숫자도 모두 제거
- StopAnalyzer : SimpleAnalyzer + 불용어 제거(the, a 등)
- StandardAnaylzer : 루씬에 내장된 가장 섬세한 분석기. 회사 이름, 이메일 주소, 도메인 이름 등 다양한 토큰을 인식하고 별도로 분리. 소문자 변환, 불용어 제거, 특수기호 제거 처리
4.1.1 색인 과정의 분석기
- 문서 색인을 위해서는 해당 문서의 필드 안에 있는 모든 텍스트에서 토큰 추출이 필요
- 문서 색인 IndexWriter 인스턴스 생성 시 Anaylzer 인스턴스를 지정
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
IndexWriter writer = new IndexWriter(directory, analyzer, IndexWriter.MaxFieldLength.UNLIMITED);

4.1.2 QueryParser와 분석기
- QueryParser 내부에서 분석기를 통해 사용자가 입력한 텍스트에서 토큰을 추출하고 질의로 변환
- 연산자, 괄호, 범위, 와일드카드, 퍼지검색 등의 표현식 문법은 제외하고 검색어만 분석
QueryParser parser = new QueryParser(Version.LUCENE_30, "contents", analyzer);
Query query = parser.parse(expression);
4.1.3 파싱과 분석의 차이점
- 분석기는 필드 단위의 텍스트를 가져와 토큰을 추출하며, 새로운 필드를 생성하지는 않음
- 파일의 내용을 필드로 생성하는 작업은 파싱
4.2 분석기 내부 구조
Analyzer 클래스
- 모든 분석기 클래스의 최상위 추상 클래스
- 입력받은 텍스트를 인련의 토큰으로 변환하며, 토큰은 TokenStream 클래스로 표현
public TokenStream tokenStream(String fieldName, Reader reader)
LowerCaseTokenizer 클래스
- 글자가 아닌 모든 숫자나 기호를 기준으로 토큰을 분리, 토큰의 글자는 소문자 처리
reusableTokenStream 메소드
- TokenStream 객체를 재사용하기위해 사용
4.2.1 토큰
- 문자열 및 메타정보(전체 텍스트의 시작/끝 지점, 토큰의 종류, 위치 증가 값 등)를 담는다.

- 시작/끝 지점 : 토큰 문자열의 시작, 마지막 글자 위치. 검색 질의와 일치하는 부분을 하이라이팅 할 때 유용
- 토큰의 종류 : 문자열로 지정. 기본값은 'word'
- 위치 증가 값 : 직전 토큰과의 상대적인 위치
토큰으로 텀 생성
- 색인 과정에서 확보한 토큰을 텀의 형태로 색인에 추가
- 메타 정보 중 토큰의 종류와 플래그는 색인에 보관되지 않고 제거
위치 증가 값
- 현재 토큰와 직전 토큰의 상대적인 위치
- 각 토큰이 얼마나 멀리 떨어져 있는지 파악할 때 필요
- 위치 증가 값이 1보다 크다 = 토큰 사이에 공간이 있거나 분석 과정에서 제거된 토큰
- 유의어는 같다는 의미로 위치 증가 값을 0으로 지정하기도 함
4.2.2 TokenStream
- 필요한 시점에 일련의 토큰을 뽑아주는 기능
TokenStream을 상속받는 클래스
- TokenFilter : 컴포지트 패턴을 따라 다른 TokenStream을 담고 있는 형태로 구성
- Tokenizer : java.io.Reader를 통해 글자를 읽어와 토큰을 생성. 다른 TokenStream에서 생성한 토큰을 받아와 추가/제거하거나 토큰의 속성을 변경하는 등의 작업을 하기에 적당


토큰과 분석 관련 루씬의 핵심 클래스


public TokenStream tokenStream(String fieldName, Reader reader){
return new StopFilter(true, new LowerCaseTokenizer(reader), stopWords);
}Reader → LowerCaseTokenizer(토큰 생성 및 소문자 변환) → StopFilter(불용어 제거 및 PositionIncrements 값 변경)
- Tokenizer 클래스 : 공백이나 숫자, 기호 등으로 토큰을 잘라낼 때까지 글자를 버퍼에 담음
- TokenFilter 클래스 : 받아오는 토큰과 추가로 준비한 토큰을 큐에 쌓고 한번에 하나씩 리턴
- TeeSinkTokenFilter 클래스 : 토큰을 싱크(sink)라 부르는 여러 개의 스트림으로 출력. 각 싱크 스트림의 내용을 받아 서로 다른 방법으로 처리할 수 있음
4.2.3 분석기 결과 확인
- 일반적으로 분석 과정에서 생성한 토큰은 그대로 색인에 추가되지만, 생성된 토큰을 직접 확인할 수도 있다.
예제 4.1 AnalyzerDemo : 분석 과정의 결과물 확인
- 두개의 문자열을 루씬의 기본 분석기로 분석하며, 분석이 끝나고 추출된 토큰을 괄호로 묶어 알기 쉽게 보여줌
public class AnalyzerDemo {
private static final String[] examples = {
"The quick brown fox jumped over the lazy dog",
"XY&Z Corporation - xyz@example.com"
};
private static final Analyzer[] analyzers = new Analyzer[] {
new WhitespaceAnalyzer(),
new SimpleAnalyzer(),
new StopAnalyzer(Version.LUCENE_30),
new StandardAnalyzer(Version.LUCENE_30)
};
public static void main(String[] args) throws IOException {
String[] strings = examples;
if (args.length > 0) { // 커맨드라인에 지정한 문자열을 분석
strings = args;
}
for (String text : strings) {
analyze(text);
}
}
private static void analyze(String text) throws IOException {
System.out.println("Analyzing \"" + text + "\"");
for (Analyzer analyzer : analyzers) {
String name = analyzer.getClass().getSimpleName();
System.out.println(" " + name + ":");
System.out.print(" ");
AnalyzerUtils.displayTokens(analyzer, text); // B
System.out.println("\n");
}
}
}
예제 4.2 AnalyzerUtils : 분석기 호출
- 분석기의 결과로 생성된 토큰을 화면에 표시
public class AnalyzerUtils {
public static void displayTokens(Analyzer analyzer, String text) throws IOException {
displayTokens(analyzer.tokenStream("contents", new StringReader(text))); //분석 프로세스 호출
}
public static void displayTokens(TokenStream stream) throws IOException {
TermAttribute term = stream.addAttribute(TermAttribute.class);
while(stream.incrementToken()) {
System.out.print("[" + term.term() + "] ");//대괄호로 묶은 토큰 텍스트 출력
}
}분석결과

토큰의 내부 구조
- TokenFilter에서 읽고 변경할 수 있는 토큰의 내부 속성 값
예제 4.3 각 토큰의 텀, 텍스트에서의 위치, 종류, 직전 토큰과의 위치를 화면에 출력하는 메소드
- displayTokensWithFullDetails 메소드 : 토큰의 내부의 정보를 화면에 출력
public static void displayTokensWithFullDetails(Analyzer analyzer, String text) throws IOException {
TokenStream stream = analyzer.tokenStream("contents", new StringReader(text)); //텍스트 분석
/*출력하고자하는 속성 준비*/
TermAttribute term = stream.addAttribute(TermAttribute.class);
PositionIncrementAttribute posIncr = stream.addAttribute(PositionIncrementAttribute.class);
OffsetAttribute offset = stream.addAttribute(OffsetAttribute.class);
TypeAttribute type = stream.addAttribute(TypeAttribute.class);
int position = 0;
while(stream.incrementToken()) { //모든 토큰을 하나씩 반복
/*텀 단위의 위치를 계산해서 출력*/
int increment = posIncr.getPositionIncrement();
if (increment > 0) {
position = position + increment;
System.out.println();
System.out.print(position + ": ");
}
/*토큰의 상세 정보 출력*/
System.out.print("[" +
term.term() + ":" +
offset.startOffset() + "->" +
offset.endOffset() + ":" +
type.type() + "] ");
}
System.out.println();
}
분석 결과
public static void main(String[] args) throws IOException {
AnalyzerUtils.displayTokensWithFullDetails(new SimpleAnalyzer(), "The quick brown fox....");
}
속성
- TokenStream에서 특정 토큰의 모든 속성을 담고 있는 단일 객체 생성은 X
- 토큰의 속성마다 개별적으로 재사용하는 속성 인터페이스를 활용
- AttributeSource 클래스를 상속받으며, 실행 시에 형변환이 필요없고 높은 확장성과 정확한 자료형 지정을 통해 성능 향상

addAttribute 메소드 호출 → 원하는 속성 클래스 인스턴스 return → TokenStream.increamentToken 메소드 호출 → 하나씩 반복
예제. 위치 증가값 속성 증가
TokenStream stream = analyzer.tokenStream("contents", new StringReader(text));
TermAttribute term = stream.addAttribute(TermAttribute.class);
PositionIncrementAttribute posIncr = stream.addAttribute(PositionIncrementAttribute.class);
while (stream.incrementToken()) {
System.out.println("posIncr=" + posIncr.getPositionIncrement());
}현재 토큰에 대한 정보를 모두 저장해뒀다가 나중에 사용하고자 할 경우
captureState 메소드 호출 -> 현재 상태를 모두 담고있는 State 객체 리턴 ->restroeState 메소드로 복원
* 성능 상 좋지 않으므로 최소화할것
토큰 종류 활용
StandardAnalyzer로 "I'll email you at xyz@example.com" 문자열 분석 시

- i'll 토큰은 하나의 단어라는 의미에서 따옴표(apostrophe)로 명시
- 단어 at은 불용어이므로 제거
- 이메일은 이메일로 명시
4.2.4 TokenFilter 순서의 중요성
- 분석기 체인의 각 단계는 앞 단계의 TokenFilter 결과물에 전적으로 의존하기 때문에, 분석기 체인 연결 순서가 매우 중요한 경우가 있음
- 소문자 제거 → 불용어 제거 → 유의어 추가
- 위와 같은 순서로 진행하지 않으면 결과 및 성능에 영향
4.3 루씬 내장 분석기

4.3.1 StopAnalyzer
- 기본적인 단어 분리 → 소문자 변경 → 불용어 제거
ENGLISH_STOP_WORDS_SET : 영어의 불용어 목록

4.3.2 StandardAnalyzer
- 일반적으로 사용하는 범용 분석기
- JFlex 기반 문법을 사용
- 글자와 숫자로 이뤄진 단어, 약어, 회사 이름, 이메일 주소, 서버 주소, 숫자, 따옴표가 포함된 단어, 인력번호, IP 주소, 중국어, 일본어 등을 인식
- StopAnalyzer와 같은 방법으로 불용어 제거
4.4 유사 발음 검색
- Apache Commons Codec 프로젝트의 Metaphone 알고리즘을 사용한 발음 기본형 분석기 구현
예제 4.5 메타폰 알고리즘을 구현한 TokenFilter 클래스
public class MetaphoneReplacementFilter extends TokenFilter {
public static final String METAPHONE = "metaphone";
private Metaphone metaphoner = new Metaphone();
private TermAttribute termAttr;
private TypeAttribute typeAttr;
public MetaphoneReplacementFilter(TokenStream input) {
super(input);
termAttr = addAttribute(TermAttribute.class);
typeAttr = addAttribute(TypeAttribute.class);
}
public boolean incrementToken() throws IOException {
if (!input.incrementToken()) //다음 토큰으로 이동
return false;
String encoded;
encoded = metaphoner.encode(termAttr.term()); //메타폰 알고리즘으로 텀 변환
termAttr.setTermBuffer(encoded); //변환된 텀을 토큰에 재설정
typeAttr.setType(METAPHONE); //토큰 종류 지정
return true;
}
}
분석기 동작 확인
public static void main(String[] args) throws IOException {
MetaphoneReplacementAnalyzer analyzer =
new MetaphoneReplacementAnalyzer();
AnalyzerUtils.displayTokens(analyzer,
"The quick brown fox jumped over the lazy dog");
System.out.println("");
AnalyzerUtils.displayTokens(analyzer,
"Tha quik brown phox jumpd ovvar tha lazi dag");
}코드 실행 결과

유사 발음 검색을 포함하면 결과 문서가 너무 많아질 수 있음
→ 구글 검색엔진은 조회 결과가 없을 때 유사 단어 조회 검색을 사용
4.5 유사어 검색
자동차 = 차량
인도요리 = 인도음식
- 유사어 지정 시에는 단어 뿐만 아니라 위치도 원본 단어와 동일해야함(위치증가값 = 0)
4.5.1 유사어 분석기 작성
예제 4.7 SynonymAnalyzer 클래스
public class SynonymAnalyzer extends Analyzer {
private SynonymEngine engine;
public SynonymAnalyzer(SynonymEngine engine) {
this.engine = engine;
}
public TokenStream tokenStream(String fieldName, Reader reader) {
TokenStream result = new SynonymFilter(
new StopFilter(true,
new LowerCaseFilter(
new StandardFilter(
new StandardTokenizer(
Version.LUCENE_30, reader))),
StopAnalyzer.ENGLISH_STOP_WORDS_SET),
engine
);
return result;
}
}- 여러 종류의 Tokenizer 클래스를 분석기 체인으로 연결
- SynonymFilter는 추가된 텀을 보관하는 버퍼로 Stack 클래스를 사용
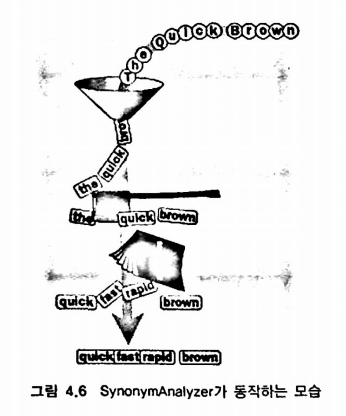
예제 4.8 SynonymFilter 유사어를 찾아 버퍼에 담고 하나씩 알려준다.
public class SynonymFilter extends TokenFilter {
public static final String TOKEN_TYPE_SYNONYM = "SYNONYM";
private Stack<String> synonymStack;
private SynonymEngine engine;
private AttributeSource.State current;
private final TermAttribute termAtt;
private final PositionIncrementAttribute posIncrAtt;
public SynonymFilter(TokenStream in, SynonymEngine engine) {
super(in);
synonymStack = new Stack<String>(); //유사어를 담아둘 버퍼
this.engine = engine;
this.termAtt = addAttribute(TermAttribute.class);
this.posIncrAtt = addAttribute(PositionIncrementAttribute.class);
}
public boolean incrementToken() throws IOException {
if (synonymStack.size() > 0) { //버퍼에 담겨있는
String syn = synonymStack.pop(); //유사어를
restoreState(current); //뽑는다
termAtt.setTermBuffer(syn);
posIncrAtt.setPositionIncrement(0); //위치증가값 0
return true;
}
if (!input.incrementToken()) //다음 토큰 읽기
return false;
if (addAliasesToStack()) { //유사어를 찾아 버퍼에 저장
current = captureState(); //현재 토큰 보관
}
return true; //현재 토큰 return
}
private boolean addAliasesToStack() throws IOException {
String[] synonyms = engine.getSynonyms(termAtt.term()); //유사어 추출
if (synonyms == null) {
return false;
}
for (String synonym : synonyms) { //유사어를 버퍼에 보관
synonymStack.push(synonym);
}
return true;
}
}- 원본 : quick → 유사어 탐색 : fast, rapid → 유사어 토큰은 buffer 저장
- 유사어도 일반 텀과 동일하게 취급되기 때문에, 유사어가 있는 단어까지 확장해서 TermQuery와 PhraseQuery가 동작
색인 과정에서 유사어 분석기 적용 시
- 색인에 추가되는 텀의 개수가 많아지면서 색인 용량이 커짐
- 유사어를 변경하거나 동적으로 색인에 반영 불가
검색 과정에서 유사어 분석기 적용 시
- 유사어 변경이 즉시 적용
- 검색할 텀의 개수가 많아져서 검색 속도 저하
4.6 기본형 분석기
PositionalPorterStopAnalyzer 클래스
- 다양한 형태로 변환된 단어를 기본형으로 반환
- 불용어 제거 / 제거된 토큰 위치 보존 / 형태소 분석
- 루씬 내장 분석기에서는 미사용
4.6.1 StopFilter와 빈 공간
- setEnablePositionIncrements 메소드 : 불용어를 제거한 빈 공간 없이 모든 위치 증가값을 1로 지정
- 불용어를 제거한 빈 공간을 무시할 시 발생할 수 있는 결과 : "one enough" = "one is not enough"
싱글 shingle
- 불용어 제거로 발생할 수 있는 문제에 대한 대안
- 서로 인접한 여러 개의 토큰을 하나로 묶어 생성한 토큰(불용어 + 다음단어 the-quick)
- 싱글 토큰을 사용하면 문서의 수가 훨씬 적어져 검색 속도 향상
4.7 필드 유형별 처리
루씬의 문서는 여러 개의 필드로 구성돼 있으며, 필드 별로 다양한 특성을 갖기 때문에 분석과정에서 많은 고려사항이 있음
4.7.1 동일한 이름의 필드
- 루씬의 문서는 동일한 이름의 Field 인스턴스를 허용(동일한 이름의 필드 내용을 연결하여 처리)
getPositionIncrementGap 메소드
- 기본값 0 (필드 값 사이에 빈 공간 없이 붙여서 처리)
- 위치 증가 값을 큰 값으로 리턴 시, 필드 경계가 명확해짐
ex) 동일한 이름의 "income tax" 필드, "return library" 필드가 있을때, "tax return" 구문의 검색 결과에 포함되는 문제 방지
같은 이름의 필드값의 요약문을 하이라이팅 시 시작점과 끝지점 지정 방법
- OffsetAttribute 속성 : 시작 지점과 끝 지점 값 설정
- endOffset 메소드 : 필드의 가장 끝 지점을 return
4.7.2 필드별 분석기 지정
- tokenStream 메소드 : 현재 처리하고있는 필드 이름을 return
- 분석기를 직접 구현 or PerFieldAnalyzerWrapper 클래스로 필드별 분석기 지정 가능
- 분석기를 직접 지정하지 않은 모든 필드는 처음 생성 시 지정한 기본 분석기를 사용
4.7.3 분석하지 않은 필드 검색
- 부품 번호, URL, 주민등록번호 등 → 분석기를 거치지않고 통째로 토큰 생성
- QueryParser 사용 시 필드마다 분석/색인했는지 여부를 모르기 때문에 처리가 어려움
(검색어 분석 → 변환 검색어로 색인 검색 → 분석되지않은 토큰 검색 실패)
해결방안
1. 사용자 인터페이스에서 별도 input 처리 (권장 X. 입력 영역이 분산되어 사용 어려움)
2. 해당 문자열을 인식해 별도의 토큰으로 분리해서 처리
3. getFieldQuery 메소드를 구현해 필드 이름 별로 처리
4. 필드별로 분석기를 지정한 PerFieldAnalyzerWrapper 객체 사용
* 색인 시 사용했던 분석 방법과 동일하게 맞추어서 처리 필요
4.8 언어별 분석
여러 언어로 작성된 원문 분석 시 주의점
1. 올바른 원문의 문자 집합(character set) 인코딩 지정
2. 언어 별로 서로 다른 불용어 처리 및 기본형 찾기 알고리즘 필요
3. 원문의 언어 파악
4.8.1 유니코드와 인코딩
- 루씬 기본 인코딩 : UTF-8
- 파일 시스템, 웹 HTML, XML 파일 등 문서마다 인코딩 지정 방법이 다름
- 외부 데이터의 인코딩 처리는 개발자의 몫
4.8.2 비영어권 언어 분석
- 불용어, 기본형 찾기 알고리즘 별도 지정이 필요
- ASCIIFoldingFilter ASCII 코드를 벗어나는 유니코드 글자를 ASCII 코드 글자로 변환
4.8.3 글자 정규화
- Reader에서 불러오는 글자를 정규화해서 Tokenizer로 넘겨주는 단계
- 필터를 거치면서 단어 변화가 있기 전, 시작과 끝 지점을 정확히 기록(하이라이팅 등의 작업 시 원문 위치에 필요)
ex) 일본어 히라가나, 가타카나 매핑 / 중국어 간체, 번체 매핑

- CharFilter를 구현하는 MappingCharFilter를 사용해 입력되는 글자를 특정 글자로 변환
- MappingCharFilter 클래스는 메모리에 수많은 임시 객체를 생성하는 방법으로 구현 - 성능 하락 이슈
- 루씬 내장 기본 분석기는 글자 필터링 기능 미사용
4.8.4 아시아 언어 분석
- CJK언어 : 한국어, 중국어, 일본어
- 표의 문자 사용, 공백 단위 단어 구분이 모호함
- StandardAnalyzer만이 CJK 언어를 유의미하게 분석
- 루씬 contrib 모듈 분석기 : CJKAnalyzer, ChineseAnalyzer, SmartChineseAnalyzer
'루씬 Lucene' 카테고리의 다른 글
| [루씬 인 액션] 6장. 검색 기능 확장 (0) | 2021.01.26 |
|---|---|
| [루씬 인 액션] 5장. 고급 검색 기법 (0) | 2021.01.10 |
| [루씬 인 액션] 3장. 검색 (0) | 2020.11.23 |
| [루씬 인 액션] 2장. 색인 (0) | 2020.11.10 |
| [루씬 인 액션] 1장. 루씬과의 만남 (0) | 2020.11.03 |



