
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 가장 큰 수
- @Data
- 검색 기능 확장
- 모던 자바 인 액션
- 알고리즘
- 다리를 지나는 트럭
- @Getter
- H-index
- K번째수
- 프로그래머스
- 롬복 어노테이션
- 영속 자료구조
- 완주하지 못한 선수
- 크론 표현식
- 코딩 테스트
- 정렬
- 해시
- 고차원 함수
- 쿠버네티스
- 스프링 스케쥴러
- 기능개발
- 루씬 인 액션
- @configuration
- 전화번호 목록
- kubenetes
- Java
- @EnableScheduling
- 스택/큐
- @Setter
- 커링
- Today
- Total
Today I Learned
[루씬 인 액션] 11장. 루씬 관리와 성능 튜닝 본문
11장에서 다루는 내용
-
성능 최적화
-
스레드 활용
-
디스크, 파일 식별자, 메모리 사용량 관리
-
색인 백업과 복원
-
색인 문제점 확인과 수정
-
흔한 오류에 대한 이해
11.1 성능 최적화
색인의 규모가 늘어나고, 검색 애플리케이션에 기능을 추가하고, 검색 요청 수가 많아짐에 따라 성능 문제가 발생할 수 있다. 이럴 경우 다양한 최적화 방법으로 루씬의 색인 또는 검색 성능을 개선할 수 있다.
11.1.1 간단한 최적화 방법
특정 지표에 대한 최적화를 수행하기 전에 간단한 최적화 절차를 먼저 살펴보자.
-
SSD 사용
-
루씬 라이브러리 버전 업그레이드
-
JVM 버전 업그레이드 및 성능 최적화
-
JVM 실행 시 -server 설정 지정
-
로컬 디스크에 색인 저장
-
자바 성능 측정 프로파일러 또는 System.nanoTime 등의 메소드로 실행시간 측정하여 딜레이되는 구간 확인
-
IndexWriter, IndexReader, IndexSearcher 등은 필요할 때만 다시 열고, 최대한 공유해서 사용
-
멀티 스레드 활용
-
물리 장비 성능 개선
-
예상되는 최대 사용량에 대비해 장비 구성
-
사용하지 않는 필드 또는 기능 제거
-
단독으로 사용하지 않는 여러 필드는 하나의 필드로 구성
11.1.2 성능 측정
최적화하고자 하는 성능 지표를 단순하고 반복적으로 측정할수 있는 방법을 만들어야 한다.
contrib/benchmark 모듈 : 반복적인 성능 측정 기능을 작성하고 실행하기에 유용한 도구
사과와 오렌지
루씬은 주기적으로 색인을 병합하기 때문에 서로 다른 설정으로 색인 테스트를 두번 진행하면 각 결과 색인이 서로 다른 병합 단계에 있을 가능성이 높다.
ex) 첫번째 색인은 막판에 병합 작업을 거쳐 3개의 세그먼트만 가지고 있지만, 두 번째 색인은 17개의 세그먼트를 가지고 있을 수 있음
이런 경우 첫번째 색인에 더 많은 시간이 투입되었기 때문에 공정하게 성능을 판단할 수 없다.
사과와 오렌지를 놓고 비교하는 꼴이다.
해결책 - mergeFactor에 큰 값을 지정해 사실상 병합 기능을 꺼버리자
시간을 측정할 때는 IndexWriter의 close 메소드의 호출 시간도 포함해야한다.
close 메소드는 메모리에 쌓여있는 문서를 색인에 밀어넣고, 병합 작업을 진행하고, 진행중인 병합이 완료되기를 기다리기도 한다.
11.1.3 색인 후 검색까지 걸리는 시간 최적화
색인 후 검색까지 걸리는 시간은 문서의 변경사항이 검색 결과에 반영되는 시간을 말한다.
IndexReader는 항상 자신이 열리던 시점의 색인을 기준으로 동작하기 때문에 색인 후 검색까지 시간을 줄이려면 IndexReader를 자주 다시 열어야한다.
준실시간(NRT. near-real-time) 검색 기능을 사용하면 시간을 최소화할 수 있다.
색인 후 검색까지 걸리는 시간을 최소화하게 도와주는 몇 가지 방법
-
IndexWriter.setMergedSegmentWarmer 메소드를 호출해 IndexWirter에서 병합한 색인 세그먼트를 검색하기 전에 워밍업해둔다.
-
BalanceMergePolicy를 사용해 대형 작업의 빈도수를 최소화한다.
-
maxBufferedDocs 설정에 좀 더 작은 값을 지정한다. IndexReader를 다시 열지 않아도 조그만 세그먼트가 알아서 저장되기 때문에 IndexReader를 새로 여는 시간을 최소화할 수 있다.
-
문서를 추가하는 경우 updateDocument 대신 addDocument 메소드를 사용한다. updateDocument는 삭제된 문서가 없는 경우에도 삭제된 텀에 대한 검색 질의를 실행하여 부하가 발생한다.
11.1.4 색인 속도 최적화
색인 속도는 색인에 초당 몇 개의 문서를 추가할 수 있는지를 말하며, 색인을 구축하거나 일괄 작업으로 문서를 추가할 때 걸리는 시간을 좌우한다.

예제 11.1 위키피디아 문서를 색인하는 성능 측정 알고리즘
# The analyzer to use
analyzer=org.apache.lucene.analysis.standard.StandardAnalyzer
# Content source
content.source=org.apache.lucene.benchmark.byTask.feeds.LineDocSource
# Directory
directory=FSDirectory
# Turn on stored fields
doc.stored = true
# Turn on term vectors
doc.term.vectors = true
docs.file=/x/lucene/enwiki-20090306-lines.txt
# Repeat 3 times
{"Rounds"
# Clear the index
ResetSystemErase
# Name the contained tasks "BuildIndex"
{"BuildIndex"
# Create a new IndexWriter
-CreateIndex
# Add all docs
{ "AddDocs" AddDoc > : 200000
# Close the index
-CloseIndex
}
# Start a new round
NewRound
} : 3
# Report on the BuildIndex task
RepSumByPrefRound BuildIndex
실행결과

색인 속도를 향상시킬 수 있는 몇 가지 팁
-
스레드를 사용한다.
-
IndexWriter에서 문서의 개수 대신 메모리 사용량 기준으로 문서를 디스크에 저장하도록 설정한다.
-
통합 색인 형식 미사용 설정한다. 색인 파일을 하나로 통합해 유지하려면 추가적인 부하가 발생한다.
-
Document 객체와 Field 객체를 재사용한다.
-
mergeFactor에 다른 값을 설정한다. mergeFactor의 값이 커지면 색인 도중 병합에 소모하는 시간이 줄어드는 반면, 검색할 때 훨씬 많은 수의 세그먼트를 사용해야 한다.
-
optimize 메소드는 꼭 필요할 때 최소한으로 사용하고, 대신 optimize(maxNumSegements) 메소드를 사용한다. optimize(maxNumSegements) 메소드는 세그먼트를 모두 묶어 하나로 만드는 대신 maxNumSegements 개의 세그먼트만 최적화하기 때문에 자원이 절약된다.
-
여러 개의 장비에서 각자의 디스크에 색인한 다음, 색인이 모두 완료되면 IndexWriter.addIndexsNoOptimize 메소드를 사용해 색인을 하나로 병합한다.
-
알고리즘 파일에서 ReadTokens 작업을 사용해 문서를 읽고 토큰을 분리하는데 걸리는 시간을 확인해보자. ReadTokens 작업은 지정한 분석기를 사용해 문서의 각 필드에 담겨있는 텍스트에서 토큰을 추출한다. 그리고 문서를 색인하지는 않는다. 따라서 문서를 생성하고 토큰을 추출하는 작업에 대한 성능을 측정할 수 있다.
예제 11.2 스레드를 사용하고, 통합 색인 형식을 사용하지 않고, 메모리를 더 많이 활용하고, mergerFactor 값을 높게 지정한 성능 측정 알고리즘
# The analyzer to use
analyzer=org.apache.lucene.analysis.standard.StandardAnalyzer
# Content source
content.source=org.apache.lucene.benchmark.byTask.feeds.LineDocSource
# Directory
directory=FSDirectory
docs.file=/x/lucene/enwiki-20090306-lines.txt
# Turn on stored fields
doc.stored = true
# Turn on term vectors
doc.term.vectors = true
ram.flush.mb = 128
# Don't use compound-file format
compound = false
merge.factor = 30
log.step = 1000
# Repeat 3 times
{"Rounds"
# Clear the index
ResetSystemErase
# Name the contained tasks "BuildIndex"
{"BuildIndex"
# Create a new IndexWriter
-CreateIndex
# Add all docs
[ { "AddDocs" AddDoc > : 40000 ] : 5 //5개의 스레드를 병렬로 실행
# Close the index
-CloseIndex
}
# Start a new round
NewRound
} : 3
# Report on the BuildIndex task
RepSumByPrefRound BuildIndex
실행결과

11.1.5 검색 처리량과 대기 시간 최적화
검색 대기 시간은 사용자가 질의를 전달한 후 결과를 받아볼 때까지 걸리는 시간, 검색 처리량은 검색 애플리케이션에서 단위 시간 안에 몇 건의 검색 요청을 처리할 수 있는지를 뜻한다.
검색 성능을 개선하는 몇 가지 팁
-
IndexReader 인스턴스를 읽기 전용으로 설정한다. 일부 정보에 대한 동기화 작업이 필요하지 않기 때문에 병렬 처리 성능이 훨씬 나아진다.
-
윈도우 서버가 아닌 다른 운영체제를 사용하고 있다면 FSDirectory 대신 더 나은 병렬 처리 기능을 제공하는 NIOFSDirectory를 사용한다. 64비트 JVM을 사용해 메모리 공간에 여유가 있다면 MMapDirectory를 사용할 수 있다.
-
사용자와 루씬이 서로 움직이는 과정에 불필요한 대기 시간이 발생하지 않도록 한다. 선입선출 방식으로 요청을 받아오고, 검색 결화를 화면에 표시하는 작업의 성능도 확인한다.
-
다중 스레드를 활용한다.
-
실제 검색 요청을 처리하기 전에 워밍업을 한다. 정렬 가능성이 있는 필드를 모두 정렬 조건으로 넣은 검색 질의를 싱행해 필드 캐시를 미리 채울 수 있다.
-
메모리가 충분하다면 저장해둔 필드의 값 대신 필드 캐시의 값을 사용한다. 필드 캐시는 필드별로 색인에 저장된 값을 메모리에 미리 올려두고 있다. 반면, 색인에 저장된 값을 가져오려면 매번 디스크에서 값을 읽어 와야 한다.
-
mergeFactor에 작은 값을 지정해 색인에 들어있는 세그먼트 수를 줄인다.
-
통합 색인 형식을 사용하지 않는다.
-
텀 벡터는 반드시 사용해야하는 상황에 필요한 결과에 대해서만 불러온다.
-
색인에 저장된 필드 값을 불러올 때는 FieldSelector를 사용해 꼭 필요한 필드 값만 불러온다.
-
optimze 또는 optimze(maxNumSegments) 메소드를 주기적으로 호출해 색인을 최적화한다.
-
결과 목록 중 필요한 개수만큼만 색인에서 불러온다.
-
IndexReader는 반드시 필요할 때만 제한적으로 다시 열어 사용한다.
-
query.rewrite().toString() 메소드의 호출해 루씬이 실제로 색인에서 찾아내는 질의를 볼 수 있다.
-
FuzzyQuery 질의를 사용한다면 접두어의 최소 길이를 0보다 큰 값으로 설정한다. minimumSimilarity 값도 가능한 큰 값으로 지정한다.
11.2 스레드와 병렬 처리
루씬은 스레드 안정성을 확보하고 있으며, 루씬을 최대한 활용하기 위해서는 다중 스레드를 적절히 활용하는게 중요하다. 물론 다중 스레드로 인해 발생할 수 있는 데드락이나 동기화 문제등에 대한 주의가 필요하다.
11.2.1 병렬 색인
ThreadedIndexWriter : IndexWriter를 상속받고 java.util.concurrent 패키지의 병렬 처리 기능을 활용해 병렬로 문서를 추가하거나 변경하는 기능을 제공한다.

예제 11.3 색인 작업을 병렬로 처리하는 ThreadedIndexWriter
public class ThreadedIndexWriter extends IndexWriter {
private ExecutorService threadPool;
private Analyzer defaultAnalyzer;
private class Job implements Runnable { //추가할 문서 하나를 나타내는 클래스
Document doc;
Analyzer analyzer;
Term delTerm;
public Job(Document doc, Term delTerm, Analyzer analyzer) {
this.doc = doc;
this.analyzer = analyzer;
this.delTerm = delTerm;
}
public void run() { //문서를 추가하거나 변경하는 실제 작업 진행
try {
if (delTerm != null) {
ThreadedIndexWriter.super.updateDocument(delTerm, doc, analyzer);
} else {
ThreadedIndexWriter.super.addDocument(doc, analyzer);
}
} catch (IOException ioe) {
throw new RuntimeException(ioe);
}
}
}
public ThreadedIndexWriter(Directory dir, Analyzer a,
boolean create, int numThreads,
int maxQueueSize, IndexWriter.MaxFieldLength mfl)
throws CorruptIndexException, IOException {
super(dir, a, create, mfl);
defaultAnalyzer = a;
threadPool = new ThreadPoolExecutor( //스레드 풀 생성
numThreads, numThreads,
0, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(maxQueueSize, false),
new ThreadPoolExecutor.CallerRunsPolicy());
}
public void addDocument(Document doc) { //스레드 풀에 작업 추가
threadPool.execute(new Job(doc, null, defaultAnalyzer));
}
public void addDocument(Document doc, Analyzer a) {
threadPool.execute(new Job(doc, null, a));
}
public void updateDocument(Term term, Document doc) {
threadPool.execute(new Job(doc, term, defaultAnalyzer));
}
public void updateDocument(Term term, Document doc, Analyzer a) {
threadPool.execute(new Job(doc, term, a));
}
public void close()
throws CorruptIndexException, IOException {
finish();
super.close();
}
public void close(boolean doWait)
throws CorruptIndexException, IOException {
finish();
super.close(doWait);
}
public void rollback()
throws CorruptIndexException, IOException {
finish();
super.rollback();
}
private void finish() { //스레드풀 종료
threadPool.shutdown();
while(true) {
try {
if (threadPool.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS)) {
break;
}
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
throw new RuntimeException(ie);
}
}
}
}
성능 측정 프레임워크에서 ThreadedIndexWriter 클래스를 사용하게 설정하고 성능을 측정해보자.
예제 11.4 성능 측정 모듈에 ThreadedIndexWriter를 사용하는 색인 작업 클래스 추가
public class CreateThreadedIndexTask extends CreateIndexTask {
public CreateThreadedIndexTask(PerfRunData runData) {
super(runData);
}
public int doLogic() throws IOException {
PerfRunData runData = getRunData();
Config config = runData.getConfig();
IndexWriter writer = new ThreadedIndexWriter(
runData.getDirectory(),
runData.getAnalyzer(),
true,
config.get("writer.num.threads", 4),
config.get("writer.max.thread.queue.size", 20),
IndexWriter.MaxFieldLength.UNLIMITED);
CreateIndexTask.setIndexWriterConfig(writer, config);
runData.setIndexWriter(writer);
return 1;
}
}
-
CreateIndex 작업 대신 CreateThreadIndex 작업을 사용한다.
-
doc.reuse.fiedls = false 설정을 추가해 DocMaker 작업이 Field 인스턴스를 재사용하지 않게 한다.
-
상황에 따라 writer.num.thrads 설정과 writer.max.thread.queue.size 설정에 원하는 값을 지정해 성능을 측정한다.
11.2.2 병렬 검색
다중 스레드를 사용할 때 IndexReader를 다시 여는 작업에는 주의가 필요하다. 일부 스레드가 IndexReader를 사용하고 있는 중이라면, 검색 결과에 문제가 생길 수 있다.
SearcherManager 클래스는 이러한 부분을 처리해준다. IndexWriter를 기반으로 생성해 준실시간 검색 기능을 사용하거나, IndexWriter를 직접 사용하기 어려운 경우 Directory 인스턴스를 기반으로 생성해 사용할 수 있다.
예제 1.5 다중 스래드 환경에서 IndexSearcher를 관리해주는 SearcherManager 클래스
public class SearcherManager {
private IndexSearcher currentSearcher; //현재 IndexSearcher 인스턴스를 보관
private IndexWriter writer;
public SearcherManager(Directory dir) throws IOException { //1
currentSearcher = new IndexSearcher(IndexReader.open(dir)); //Direcotry 인스턴스로 IndexSearcher 생성
warm(currentSearcher);
}
public SearcherManager(IndexWriter writer) throws IOException { //2
this.writer = writer;
currentSearcher = new IndexSearcher(writer.getReader()); //IndexWriter에서 준실시간 검색용 IndexSearcher 생성
warm(currentSearcher);
writer.setMergedSegmentWarmer( // 3
new IndexWriter.IndexReaderWarmer() {
public void warm(IndexReader reader) throws IOException {
SearcherManager.this.warm(new IndexSearcher(reader));
}
});
}
public void warm(IndexSearcher searcher) //하위 클래스에서 구현
throws IOException {}
private boolean reopening;
private synchronized void startReopen()
throws InterruptedException {
while (reopening) {
wait();
}
reopening = true;
}
private synchronized void doneReopen() {
reopening = false;
notifyAll();
}
public void maybeReopen() //IndexSearcher를 다시 연다.
throws InterruptedException, IOException {
startReopen();
try {
final IndexSearcher searcher = get();
try {
IndexReader newReader = currentSearcher.getIndexReader().reopen();
if (newReader != currentSearcher.getIndexReader()) {
IndexSearcher newSearcher = new IndexSearcher(newReader);
if (writer == null) {
warm(newSearcher);
}
swapSearcher(newSearcher);
}
} finally {
release(searcher);
}
} finally {
doneReopen();
}
}
public synchronized IndexSearcher get() { //현재 IndexSearcher 리턴
currentSearcher.getIndexReader().incRef();
return currentSearcher;
}
public synchronized void release(IndexSearcher searcher) //IndexSearcher 해제
throws IOException {
searcher.getIndexReader().decRef();
}
private synchronized void swapSearcher(IndexSearcher newSearcher)
throws IOException {
release(currentSearcher);
currentSearcher = newSearcher;
}
public void close() throws IOException {
swapSearcher(null);
}
}SearcherManager 클래스는 IndexReader.reopen 메소드를 최대한 활용하며, reopen 메소드는 앞서 열려있던 IndexReader 인스턴스에서 이미 열고 있던 SegmentReader 인스턴스를 그대로 물려받는다.
(2) 색인에 변경 사항을 추가하는 IndexWriter 인스턴스의 메소드를 직접 호출할 수 있다면 IndexWriter 인스턴스를 사용해 SearcherManager 인스턴스를 생성하자. IndexWriter의 준실시간 검색 기능을 활용할 수 있다.
(3)또한 setMergedSegmentWarmer 메소드를 호출해 병한한 세그먼트를 자동으로 워밍업한다.
(1) 그렇지않다면 IndexWriter 대신 Directory 인스턴스를 사용해 SearcherManager 인스턴스를 생성한다. 그러면 SearcherManager 내부에서 IndexSearcher 인스턴스를 생성한다.
SearcherManager 클래스는 IndexReader를 자체적으로 다시열지는 않으며, maybeReopen 메소드를 필요할때마다 호출해야한다.
11.3 자원 관리
루씬이 동작하면서 하드웨어의 자원을 어떻게 사용하는지에 대해 충분히 이해하고 필요한 경우에 원하는 방향으로 제어할 수 있어야 검색 애플리케이션이 안정적으로 동작하게 환경을 구성할 수 있다.
11.3.1 디스크
루씬의 디스크 사용량은 여러 가지 요소를 기반으로 움직인다.
단 하나의 색인된 텍스트 필드가 들어있는 색인은 원문 대비 1/3 수준의 용량을 차지한다.
반면, 저장된 필드에 텀 벡터와 시작 및 끝 지점, 텀의 위치 등이 모두 들어있고, 삭제된 문서가 많이 남아있으며, 현재 색인을 열고 있는 IndexReader 인스턴스를 사용중이며, 동시에 최적화 작업이 진행되는 경우라면 원문 용량의 10배를 차지하기도 한다.

위키피디아 문서 색인에 대한 최종 디스크 사용량은 14.2GB이지만, 여러 개의 대형 병합 작업이 동시에 진행될 때는 32.4GB의 최대 사용량을 기록했다.
문서 전체의 텍스트 용량을 기반으로 최종 색인의 용량을 가늠하는 대략적인 공식은 다음과 같다.

디스크 사용량을 줄이는 방법
-
norm을 사용하지 않는다.
-
텀 빈도수 정보를 사용하지 않는다.
-
텀 벡터를 저장하면서 시작 및 끝 지점과 텀의 위치 정보를 사용하지 않는다.
-
문서에서 색인하거나 저장하는 필드의 수를 최소화한다.
임시 디스크 사용량을 좌우하는 요인
-
열러있는 IndexReader 인스턴스가 있다면 해당 IndexReader에서 사용하고 있는 세그먼트는 삭제할 수 없다. IndexReader를 다시 여는 동안을 제외하고는 항상 단 하나의 인스턴스만 사용하자.
-
현재 IndexWriter 인스턴스를 열 때 존재하던 모든 세그먼트 뿐만 아니라 현재 커밋 지점에서 참조하는 세그먼트는 그대로 유지된다. 커밋을 자주 사용하면 임시 디스크 사용량은 줄어들지만, 색인 속도에 영향을 주게 된다.
-
삭제된 문서는 optimize 메소드를 호출해 병합 작업을 진행해야 실제 공간이 비워진다.
-
색인 안에 세그먼트 개수가 많을수록(mergeFactor 설정이 높을수록) 병합된 상태보다 더 많은 디스크 공간을 소모한다.
-
텍스트 양이 많은 소수의 문서를 색인할 때 보다 텍스트 양이 적은 다량의 문서를 색인할 때 더 많은 디스크 공간을 차지한다.
-
optimze 메소드를 실행하고 있거나 병합 작업이 진행되고 있는 도중 IndexReader를 새로 열면, 병합 작업 후에 삭제될 세그먼트를 참조하기 때문에 병합 작업이 끝나도 세그먼트가 남아있게 된다.
-
IndexWriter에서 변경 사항을 반영한 후 기존에 사용하던 IndexReader는 닫아야한다. 그렇지 않으면 병합 작업으로 인해 IndexWriter에서 삭제하고자 하는 세그먼트를 기존의 IndexReader에서 계속 참조해 삭제할 수 없다.
-
핫 백업을 사용하고 있다면 현재 복사하는 스냅샷 파일 역시 계속 디스크 공간을 점유하며, 스냅샷을 해제할 때 디스크 공간이 반환된다.
11.3.2 파일 식별자
색인이 충분히 최적화되었다면, 통합 파일 형식을 사용하지 않게 설정하고 mergeFactor에 적절한 값을 지정해 성능을 향상시킬 수 있다. 하지만 루씬에서 동시에 열고있어야 하는 파일의 개수가 급격히 증가한다는 문제가 생긴다. 결국 'Too many open files' 오류와 함께 파일을 더이상 사용하지 못하게 운영체제에서 제한한다.
아래 예제코드는 최대 몇개의 파일을 열 수 있는지 확인해 보여준다.
최대 파일 개방 개수는 운영체제와 JVM에 따라 천차만별이다.
public class OpenFileLimitCheck {
public static void main(String[] args) throws IOException {
List<RandomAccessFile> files = new ArrayList<RandomAccessFile>();
try {
while(true) {
files.add(new RandomAccessFile("tmp" + files.size(), "rw"));
}
} catch (IOException ioe) {
System.out.println("IOException after " + files.size() + " open files:");
ioe.printStackTrace(System.out);
int i = 0;
for (RandomAccessFile raf : files) {
raf.close();
new File("tmp" + i++).delete();
}
}
}
}최대 파일 개방 개수는 운영체제 별 명령어를 통해 늘릴 수 있다.
예제 11.6 열려있는 파일에 대한 정보를 출력하는 TrackingFSDirectory 클래스
public class TrackingFSDirectory extends SimpleFSDirectory {
private Set<String> openOutputs = new HashSet<String>(); //열려있는 모든 파일의 이름을 담는다.
private Set<String> openInputs = new HashSet<String>();
public TrackingFSDirectory(File path) throws IOException {
super(path);
}
synchronized public int getFileDescriptorCount() { //열려있는 파일의 개수를 리턴
return openOutputs.size() + openInputs.size();
}
synchronized private void report(String message) {
System.out.println(System.currentTimeMillis() + ": " +
message + "; total " + getFileDescriptorCount());
}
synchronized public IndexInput openInput(String name) //입력 파일을 여는 상황 출력
throws IOException {
return openInput(name, BufferedIndexInput.BUFFER_SIZE);
}
synchronized public IndexInput openInput(String name, int bufferSize)
throws IOException { //입력 파일을 여는 상황 출력
openInputs.add(name);
report("Open Input: " + name);
return new TrackingFSIndexInput(name, bufferSize);
}
synchronized public IndexOutput createOutput(String name)
throws IOException { //출력 파일을 여는 상황 출력
openOutputs.add(name);
report("Open Output: " + name);
File file = new File(getFile(), name);
if (file.exists() && !file.delete())
throw new IOException("Cannot overwrite: " + file);
return new TrackingFSIndexOutput(name);
}
protected class TrackingFSIndexInput extends SimpleFSIndexInput { //입력파일이 닫히는지 추적
String name;
public TrackingFSIndexInput(String name, int bufferSize) throws IOException {
super(new File(getFile(), name), bufferSize, getReadChunkSize());
this.name = name;
}
boolean cloned = false;
public Object clone() {
TrackingFSIndexInput clone = (TrackingFSIndexInput)super.clone();
clone.cloned = true;
return clone;
}
public void close() throws IOException {
super.close();
if (!cloned) {
synchronized(TrackingFSDirectory.this) {
openInputs.remove(name);
}
}
report("Close Input: " + name);
}
}
protected class TrackingFSIndexOutput extends SimpleFSIndexOutput { //출력파일이 닫히는지 추적
String name;
public TrackingFSIndexOutput(String name) throws IOException {
super(new File(getFile(), name));
this.name = name;
}
public void close() throws IOException {
super.close();
synchronized(TrackingFSDirectory.this) {
openOutputs.remove(name);
}
report("Close Output: " + name);
}
}
}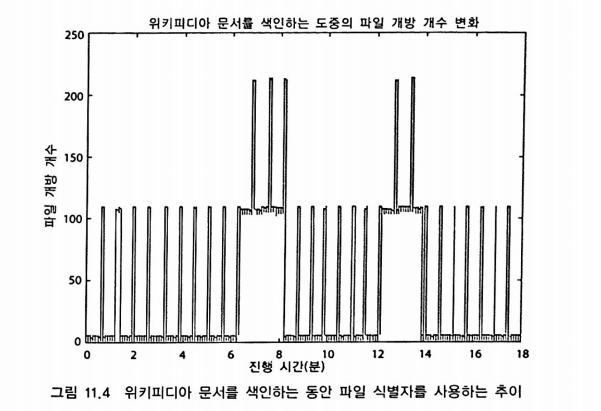
사용량이 낮은 부분은 문서를 추가하는 과정이고, 높은 부분은 병합 작업이 진행되는 부분이다. 즉, 한 번에 병합하는 세그먼트 수를 뜻하는 mergeFactor 값이 색인 과정의 파일 개방 개수에 직접적인 영향을 준다.
검색 작업 시에는 더 많은 파일을 열어야 할 수도 있다. IndexReader는 색인을 구성하는 각 세그먼트에 해당하는 모든 개별 파일을 열고 있어야 한다. 변경 사항이 자주 발생하고 규모가 계속해서 증가하는 색인인 경우 파일 개방 개수가 급격히 증가한다.
IndexReader를 다시 열 때 병합 작업이 끝나 색인이 변경됐다면 기존의 IndexReader와 새 IndexReader가 동시에 열려있는 상태이기 때문에 파일 개방 개수는 최고점을 찍는다. IndexReader.reopen 메소드를 사용하면 원래 사용중이던 세그먼트에 대한 파일 개방 개수는 그대로 유지하기 때문에 새로 열때보다는 줄어든다.
색인의 크기가 커질수록 파일 개방개수가 늘어나긴 하지만 대형 병합 작업 등을 거치기 때문에 파일 개방 개수는 선형적으로 증가하지 않는다.

색인 성능을 유지하면서 파일 개방 개수를 최소화하는 방법
-
IndexWriter의 버퍼(setRAMBufferSizeMB)를 크게 잡아준다. 세그먼트 생성 개수가 줄어서 파일 개방 개수가 줄어든다.
-
IndexReader.reopen 메소드를 활용한다.
-
mergeFactor 값을 줄인다. 너무 많이 줄이면 색인 성능이 떨어질 수 있다.
-
ConcurrentMergeScheduler.setMaxThreadCount 메소드로 동시에 병합을 진행하는 스레드의 개수를 줄인다.
-
IndexWriter.optimize(int maxNumSegments) 메소드로 부분 최적화 작업을 진행하면 최적화 작업에 걸리는 시간을 줄이면서 색인의 세그먼트 개수를 줄여 파일 개방 개수가 줄어드는 효과가 있다.
-
최대 파일 개방 개수에 항상 대비한다. 기존 IndexReader가 열려있는 상태에서 새로 IndexReader를 열고 워밍업하는 시간 등이 주로 최댓값에 해당한다.
-
색인과 검색 작업을 하나의 JVM 안에서 처리한다면 양쪽 작업에 충분할 만큼 파일 개방 개수에 여유를 둬야 한다. 가능하면 IndexReader를 다시 열기 전에 IndexWriter를 닫는 편이 좋다.
-
같은 JVM 안에서 동작하는 다른 코드에서 파일 식별자를 너무 많이 소모하는 경우는 없는지 주의한다.
-
사용하지 않는 IndexReader 인스턴가 정확하게 닫히는지 확인한다.
성능과 파일 개방 개수의 사이에서 최적의 균형점을 찾는게 중요하다.
11.3.3 메모리
최적화 작업 중 메모리 사용량을 관리하는 일은 JVM에서 운영체제의 메모리를 사용하는 부분과 검색 애플리케이션에서 JVM의 메모리를 사용하는 두 부분으로 나눌 수 있다.
JVM에게 필요한 힙 메모리의 양을 지정할 때에는 루씬이 필요로 하는만큼 여유있게 제공해야 하지만, 운영체제에서 디스크 스와핑을 하게 될 만큼 너무 크게 설정하면 안된다. 또한, 운영체제 캐시 등으로 활용할 수 있게 일정량의 메모리는 남겨두는 편이 좋다.
운영체제가 디스크 스와핑으로 성능이 떨어지는지 확인하는 방법
-
하드 디스크를 사용중이라면, 디스크 스와핑이 발생하면 디스크를 긁는 듯한 소리가 난다.
-
유닉스 환경에서는 vmstat 1 명령을 실행해 매초 가상 메모리 현황을 출력한다. 출력된 내용 중 디스크 스와핑 관련된 컬럼(si 또는 so)를 살펴본다.
윈도우 환경에서는 작업관리자 > View > Select Columns 메뉴의 Page Faults Delta 항목을 선택해 화면에 표시한 후, 각 값이 비정상적으로 높아지는지 확인한다.
-
기본적인 프로그램이 사용할 수 없을 정도로 느려지는 현상이 있는지 확인한다.
-
유닉스 환경에서 top 명령을 실행하고 Mem: 부분을 확인한다. free 부분과 buffers 부분이 0에 가까운 값이라면 문제가 있는 상황이다.
윈도후 환경에서는 작업관리자 > Performance 탭을 선택한다. Physical Memory 부분의 Available 값과 System Cache 값이 0에 가깝다면 문제가 있다. 이 값은 운영체제에서 I/O 캐시에 활용하고 있는 메모리 양이다.
-
프로세스의 CPU 사용량이 예상과 달리 너무 낮은 경우도 주의하자.
가비지 컬렉션이 발생한 직후의 힙 메모리 크기를 살펴보면, 기본적으로 사용하는 메모리의 크기를 확인할 수 있다. 검색 애플리케이션에서 JVM에서 할당된 메모리 공간을 거의 전부 활용해야한다면 계속해서 가비지 컬렉션 작업을 진행하기 때문에 성능이 크게 떨어진다.
색인 과정에서 메모리를 가장 많이 사용하는 부분 중 하나는 IndexWriter에서 사용하는 메모리 버퍼이며, setRAMBufferSizeMB 메소드로 버퍼 용량을 지정할 수 있다.
색인에 비해 검색 작업에서 메모리를 더 많이 소모한다.
검색 작업에서 메모리를 절약하는 방법
-
색인을 최적화해 삭제 표기된 문서를 실제로 제거한다.
-
필드 캐시에 읽어들이는 필드의 개수를 제한한다. 필드 캐시는 전적으로 메모리를 활용하며 불러오는데 시간도 많이 걸린다. 특히 String이나 StringIndex형 필드 캐시는 int 또는 float 등의 자료형보다 훨씬 많은 메모리를 소모한다.
-
정렬 대상 필드의 수를 제한한다. 특정 필드로 정렬하게 질의한 검색 요청을 처리할 때 해당 필드 내용을 필드 캐시에 불러온다. 비슷한 원리로 문자열 필드로는 정렬하지 않는 편이 좋다.
-
필드 norm을 사용하지 않는다. 필드 norm에는 색인 시점에 지정한 각종 중요도를 합산한 값이 들어간다. 하지만 필드 norm 값이 연관도 점수에 실제로 큰 영향을 끼치는 경우느 많지 않다.
-
상황에 맞춰 여러 필드의 내용을 하나의 필드로 묶어 검색한다. 그러면 루씬 내부에서 메모리 사용량을 줄여주며, 검색 속도도 개선되는 효과가 있다.
-
분석기에서 적절한 텀을 생성하는지 확인한다. 루크(Luke)를 활용해 색인을 열고 사용자가 검색하는 내용에 맞는 텀이 들어있는지 확인할 수 있다.
-
지금은 사용하지 않는 IndexSearcher 또는 IndexReader 인스턴스를 모두 정확하게 닫고 해제했는지 확인한다.
-
자바 메모리의 프로파일링 기능이나 소프트웨어 등을 활용해 메모리를 어디서 많이 소모하는지 확인한다.
11.4 색인 백업
예기치 못한 상황을 대비해 색인을 주기적으로 백업하고 간단한 절차를 거쳐 복원할 수 있게 준비해야 한다.
11.4.1 백업
색인을 백업하는 가장 기본적인 방법은 IndexWriter 인스턴스를 닫은 후 색인 디렉토리 안에 들어있는 모든 파일을 복사하는 방법이다.
단지 색인 파일을 복사하는 정도로는 올바르게 색인을 백업할 수 없다. IndexWriter 등이 동작하는 동안에 색인 파일을 복사하면 복원할 수 없는 경우가 많다.
루씬 2.3 버전부터는 색인의 핫 백업(hot backup)을 생성할 수 있으며, 결과적으로 IndexWriter를 닫지 않고도 최신 커밋 지점에 해당하는 파일을 정확하게 골라 백업할 수 있게 되었다.
검색 또는 색인 작업에 영향을 주지 않게 복사하는 작업의 I/O 속도를 조절하거나, 프로세스 또는 I/O 작업의 우선순위를 조절할 수 있다.
백업 작업은 반드시 해당 색인에 IndexWriter을 열고 있는 프로세스에서 진행해야 하며, IndexWriter 인스턴스를 생성할때 SnapshotDeletionPolicy를 사용해서 백업을 완료할 때까지 커밋 지점을 유지시키게해야한다.
IndexDeletionPolicy policy = new KeepOnlyLastCommitDeletionPolicy();
SnapshotDeletionPolicy snapshotter = new SnapshotDeletionPolicy(policy);
IndexWriter writer = new IndexWriter(dir, analyzer, snapshotter,
IndexWriter.MaxFieldLength.UNLIMITED);그리고 백업을 해야 할 시점에는 다음과 같은 코드를 실행한다.
try {
IndexCommit commit = (IndexCommit) snapshotter.snapshot();
Collection<String> fileNames = commit.getFileNames();
/*<iterate over & copy files from fileNames>*/
} finally {
snapshotter.release();
}스냅샷이 살아있는 동안에는 해당 스냅샷에 포함된 모든 파일이 디스크에 계속 유지되기 때문에 문서를 변경하거나 최적화 작업을 진행하더라도 문제없다.
IndexWriter에서 커밋할 때마다 덮어쓰는 segments.gen 파일은 항상 백업 대상 파일에 포함시켜야 한다. 반면 write.lock 파일은 포함시키면 안된다.
SnapshotDeletionPolicy 사용 시 주의점
-
한번에 하나의 스냅샷만 유지할 수 있다. 여러 개의 스냅샷을 유지할 필요가 있다면 별도의 SnapshotDeletionPolicy를 구현해야 한다.
-
IndexWriter를 닫고 다시 열면 스냅샷이 삭제된다. 하지만 현재 스냅샷을 디스크에 저장했다가 불러오고, IndexWriter를 새로 열어 해당 스냅샷을 보호할 수 있다.
11.4.2 복원
복원이 진행되는 일반적인 절차
-
색인 파일을 다시 되돌려 복사할 수 있게 모든 IndexReader와 IndexWriter 인스턴스를 닫는다.
-
현재 색인 디렉토리 안에 들어있는 모든 파일을 삭제한다.
-
백업된 파일을 색인 디렉토리 안에 복사한다.
11.5 일반적인 오류
11.5.1 깨진 색인
색인이 깨지는 현상이 발생할 때는 천천히 하지만 꾸준히 진행된다. 색인이 깨질때는 근본적인 원인을 찾아 해결해야 하며, 로그파일을 주의깊게 살펴보고 모든 예외 상황을 설명할 수 있어야 한다.
색인이 깨진다고 알려진 몇가지 상황
-
하드웨어 문제 : 전원 공급 장치에 문제가 있거나 물리적인 문제가 발생하기 시작한 하드디스크, 메모리 불량 등
-
실수로 두 개의 IndexWriter에 동시에 같은 색인을 변경하게 된 경우 : 루씬의 쓰기 락을 통해 거의 완벽하게 방지할 수 있다. 하지만 특정 LockFactor를 올바르게 사용하지 않거나, write.lock 파일을 임시로 삭제하는 등의 상황이 발생하면 문제가 생길 수 있다.
-
색인 복사 도중 오류 발생
-
루씬의 버그
색인이 깨졌는지 미리 확인하는 방법
-
JVM에 -ea:org.apache.lucene 등의 설정을 추가해 검증 기능을 사용한다. 루씬이 동작하면서 색인과 검색 작업의 여러 부분에서 추가적인 확인 작업을 거친다.
-
org.apache.lucene.index.CheckIndex 프로그램을 사용해 색인이 깨졌는지 확인한다. 색인의 세그먼트마다 확인 작업을 진행하며, 세그먼트마다 상세한 통계와 문제점을 화면에 출력한다.
11.5.2 색인 수리
CheckIndex 프로그램은 색인에 문제가 발생했지만 더이상 조치할 방법이 없는 경우 시도할 수 있는 방법이다.
-fix 설정을 지정해 문제점을 고치게 할 수 있으며, 문제가 발견된 세그먼트를 강제로 제거한다.
세그먼트를 제거하기 때문에 응급 상황에서 임시 방편으로 검색 서비스를 제공하려는 정도로만 활용하는 편이 좋다.
'루씬 Lucene' 카테고리의 다른 글
| [루씬 인 액션] 8장. 필수 확장 기능 (0) | 2021.02.09 |
|---|---|
| [루씬 인 액션] 6장. 검색 기능 확장 (0) | 2021.01.26 |
| [루씬 인 액션] 5장. 고급 검색 기법 (0) | 2021.01.10 |
| [루씬 인 액션] 4장. 루씬의 텍스트 분석 (0) | 2020.12.08 |
| [루씬 인 액션] 3장. 검색 (0) | 2020.11.23 |



